
计算机组成原理
🌱 一些记录? 🌱
快捷导航
计算机系统概述
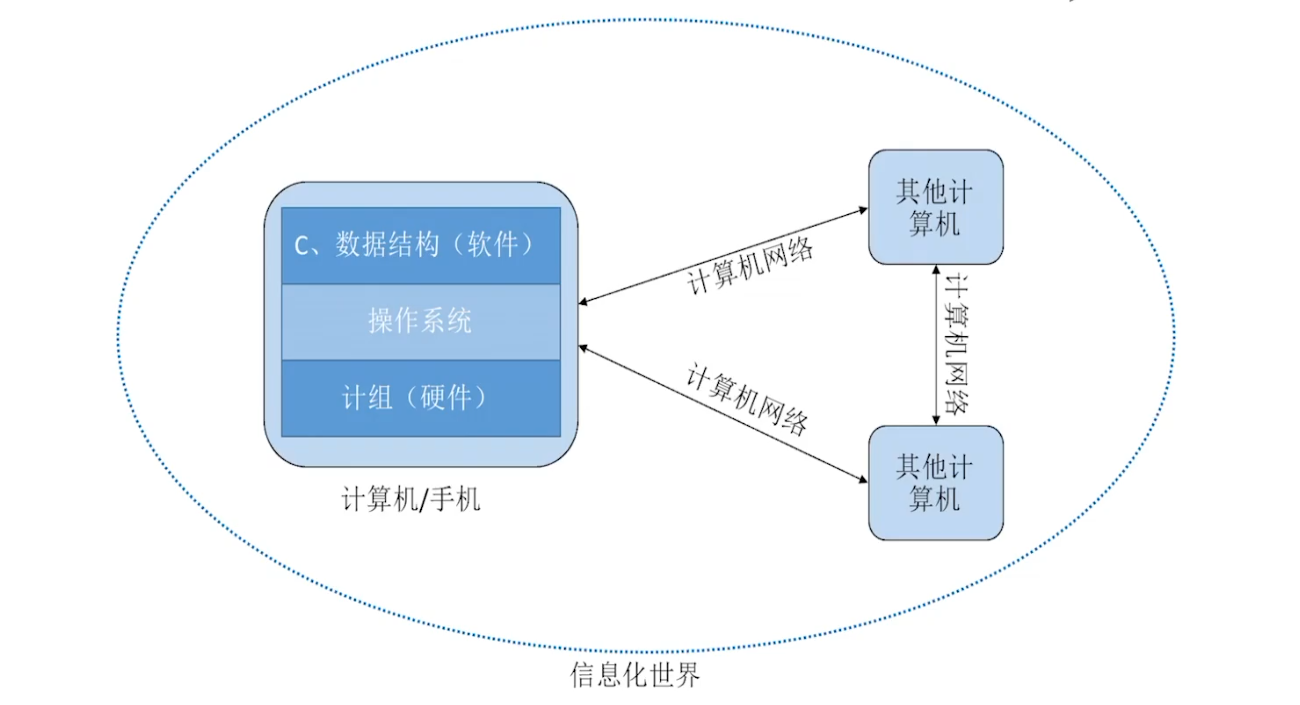
用低/高电平分别表示 0/1
计算机硬件唯一能识别的数据: 二进制 0/1
通过电信号传递数据
计算机发展历程
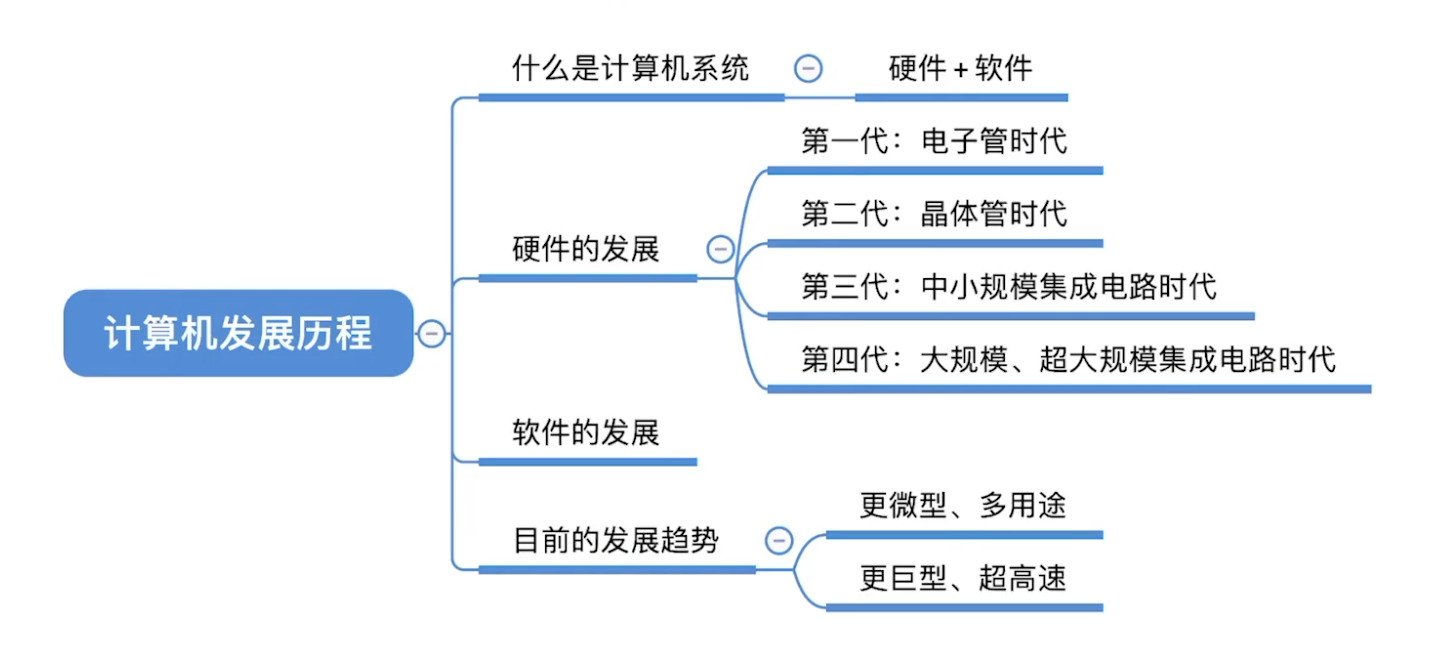
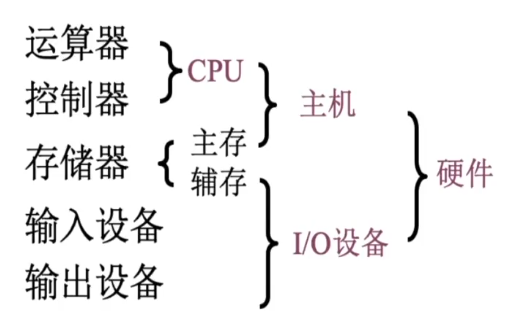
计算机系统 = 硬件 + 软件
- 硬件: 计算机的实体,如主机、外设等
- 软件: 由具有各类特殊功能的程序组成
计算机性能的好坏取决于“软”、“硬”件功能的总和
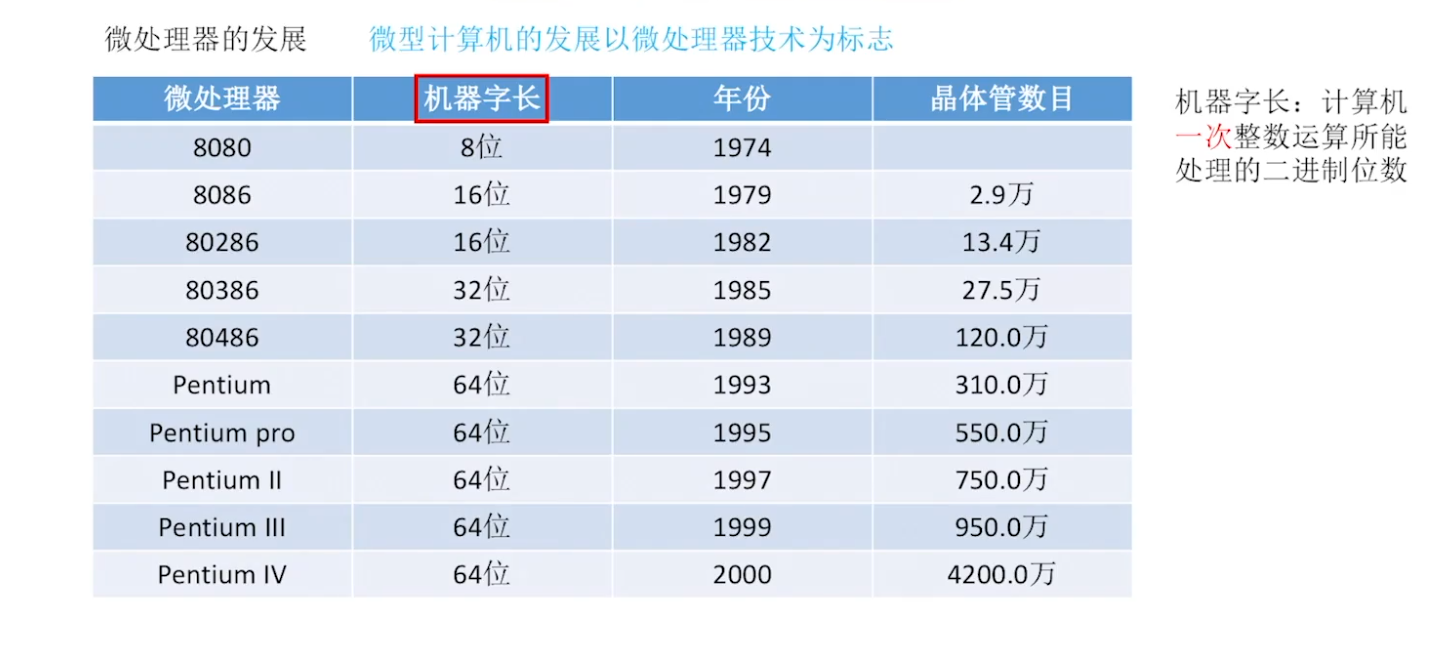
- 计算机的机器字长是指数据运算的基本单位长度
计算机硬件的基本组成
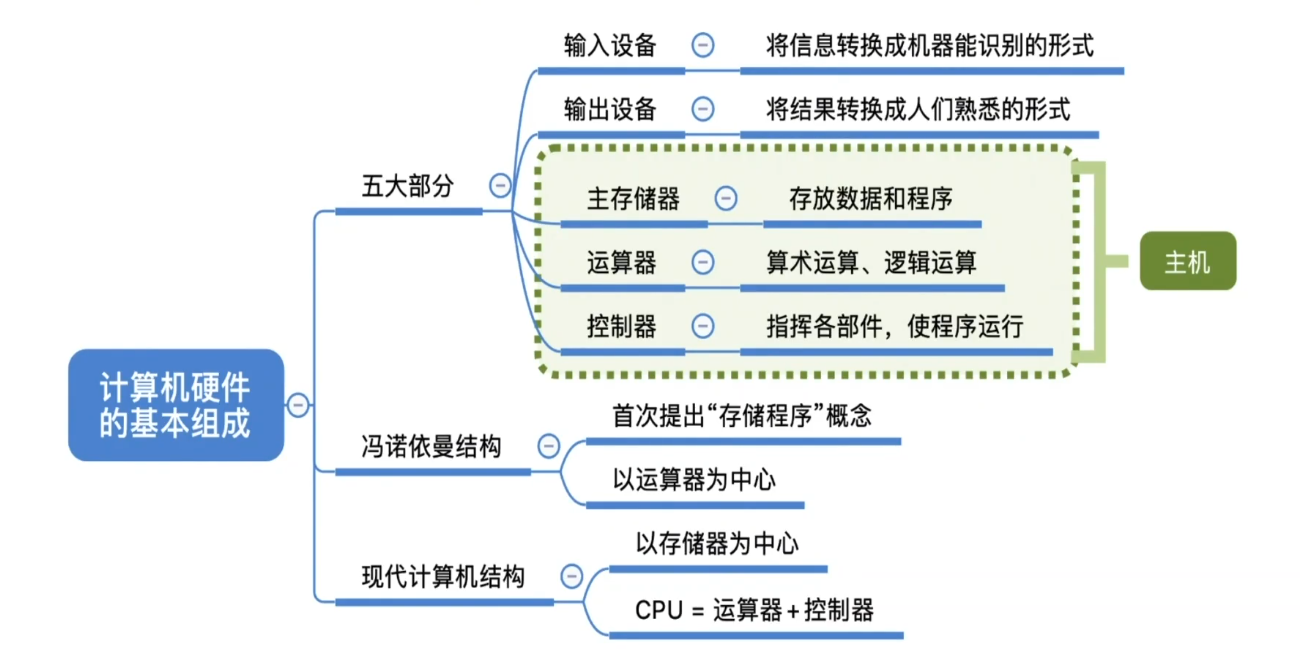
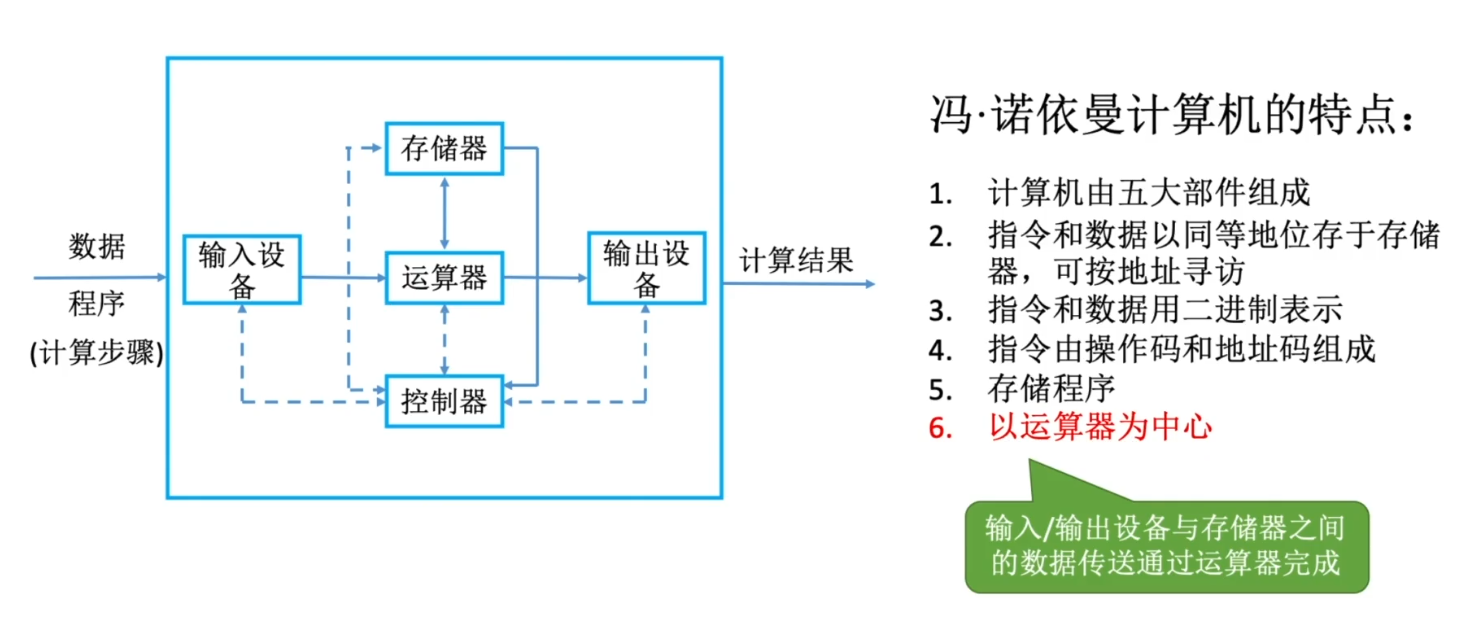
冯诺依曼结构
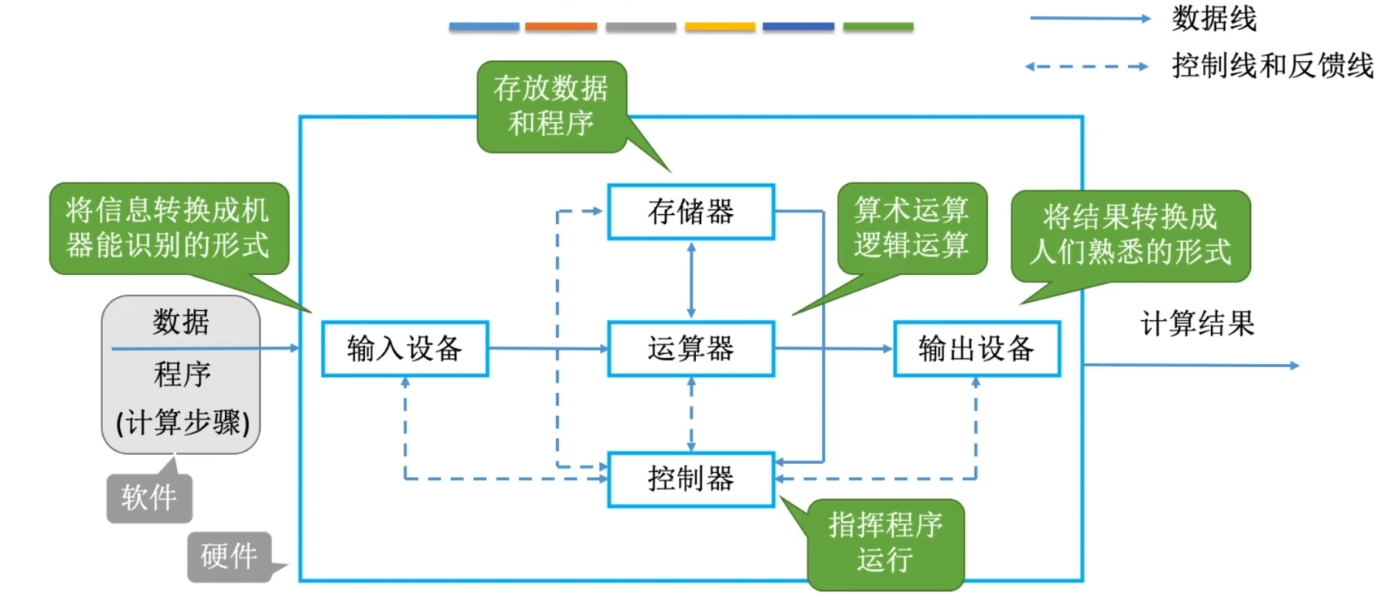
“存储程序”的概念是指将指令以二进制代码的形式事先输入计算机的主存储器,然后按其在存储器中的首地址执行程序的第一条指令,以后就按该程序的规定顺序执行其他指令,直至程序执行结束
在计算机系统中,软件和硬件在逻辑上是等效的。
Eg:对于乘法运算,可以设计一个专门的硬件电路实现乘法运算也可以用软件的方式,执行多次加法运算来实现
现代计算机结构
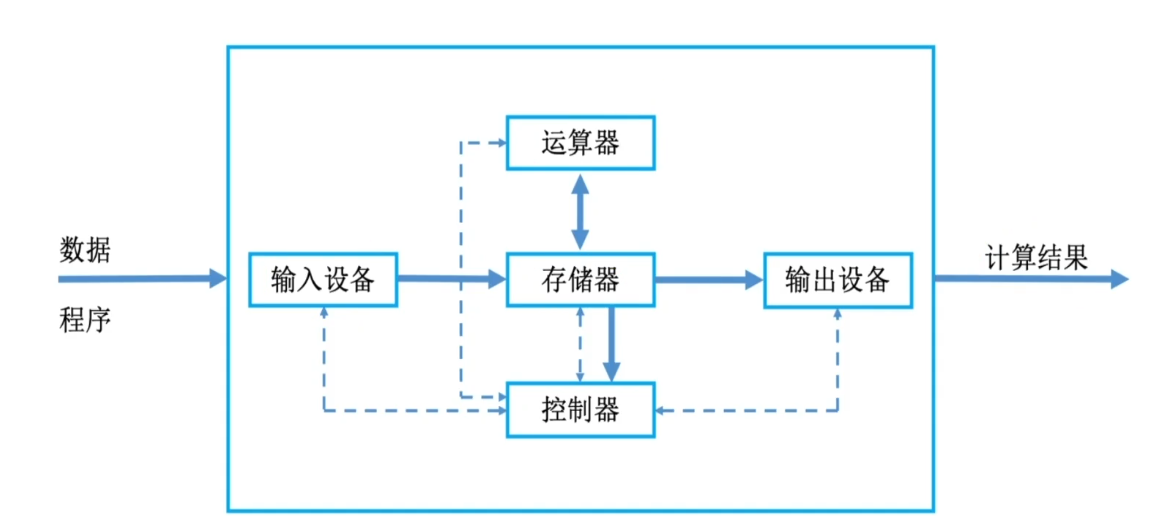
- 现代计算机:以存储器为中心
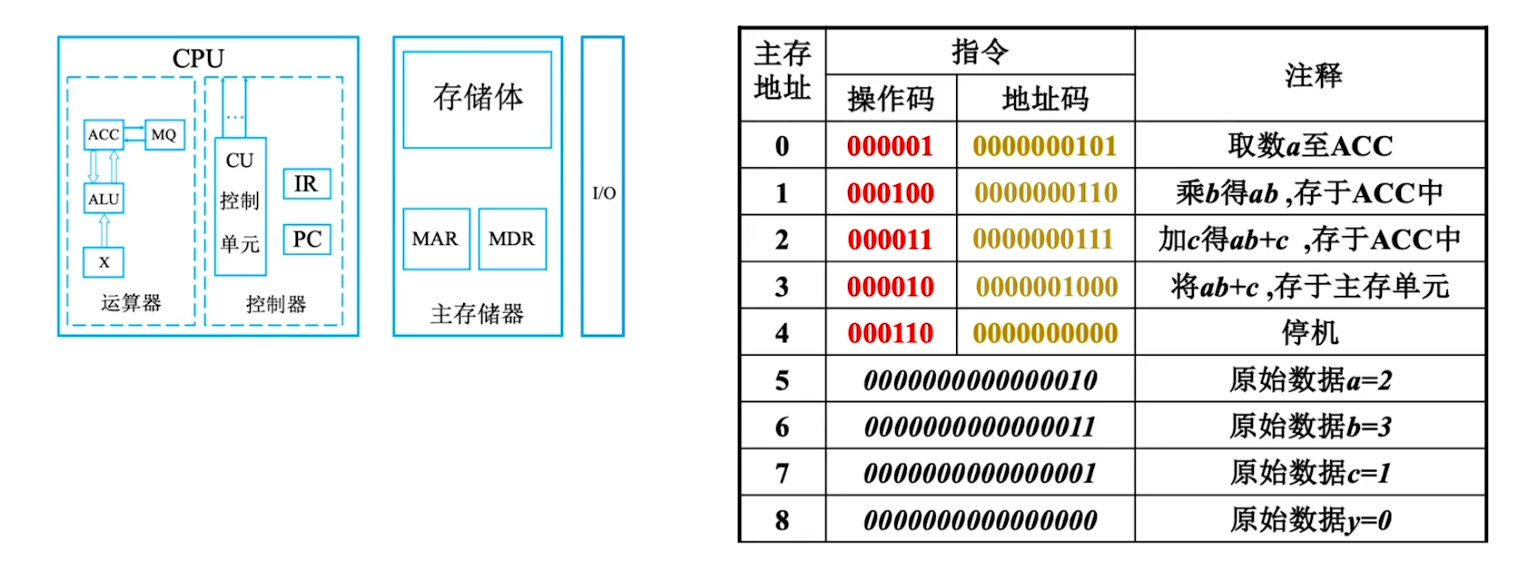
- CPU=运算器+控制器
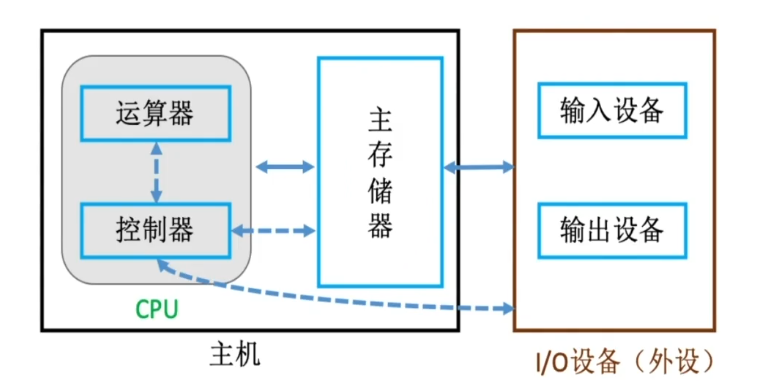
各硬件部件工作原理
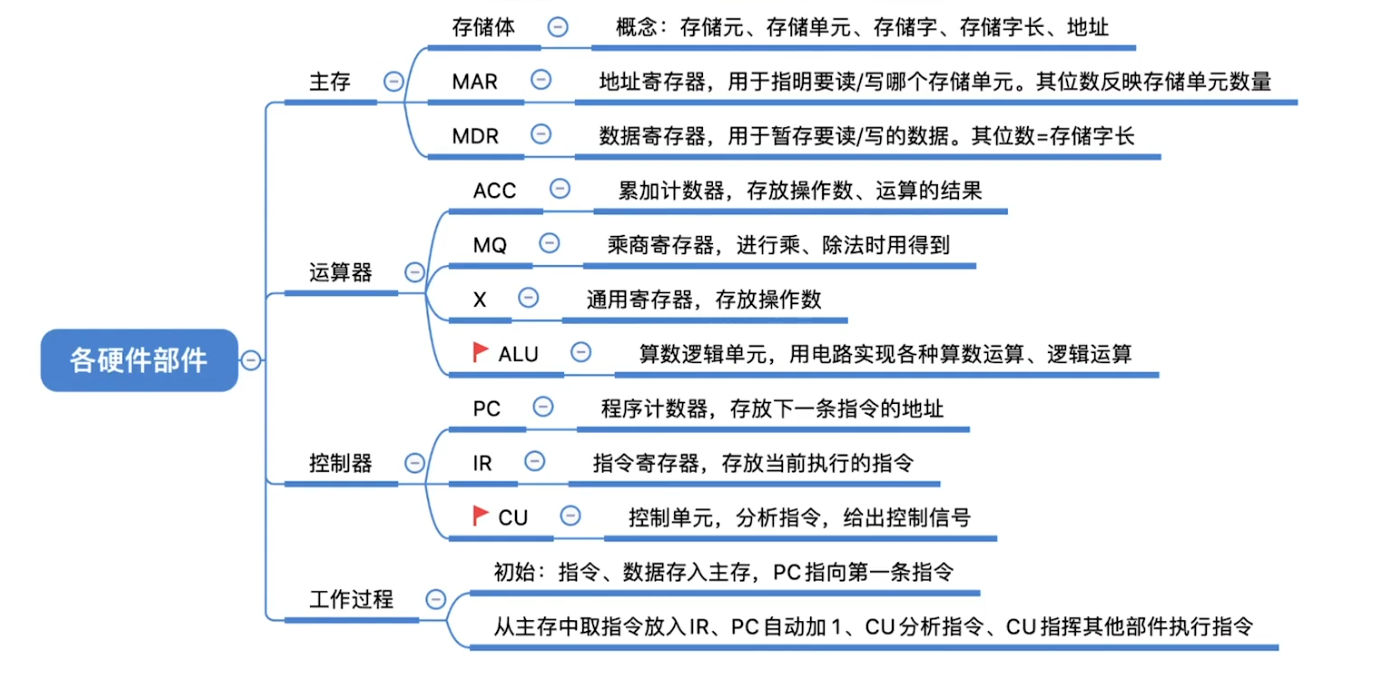
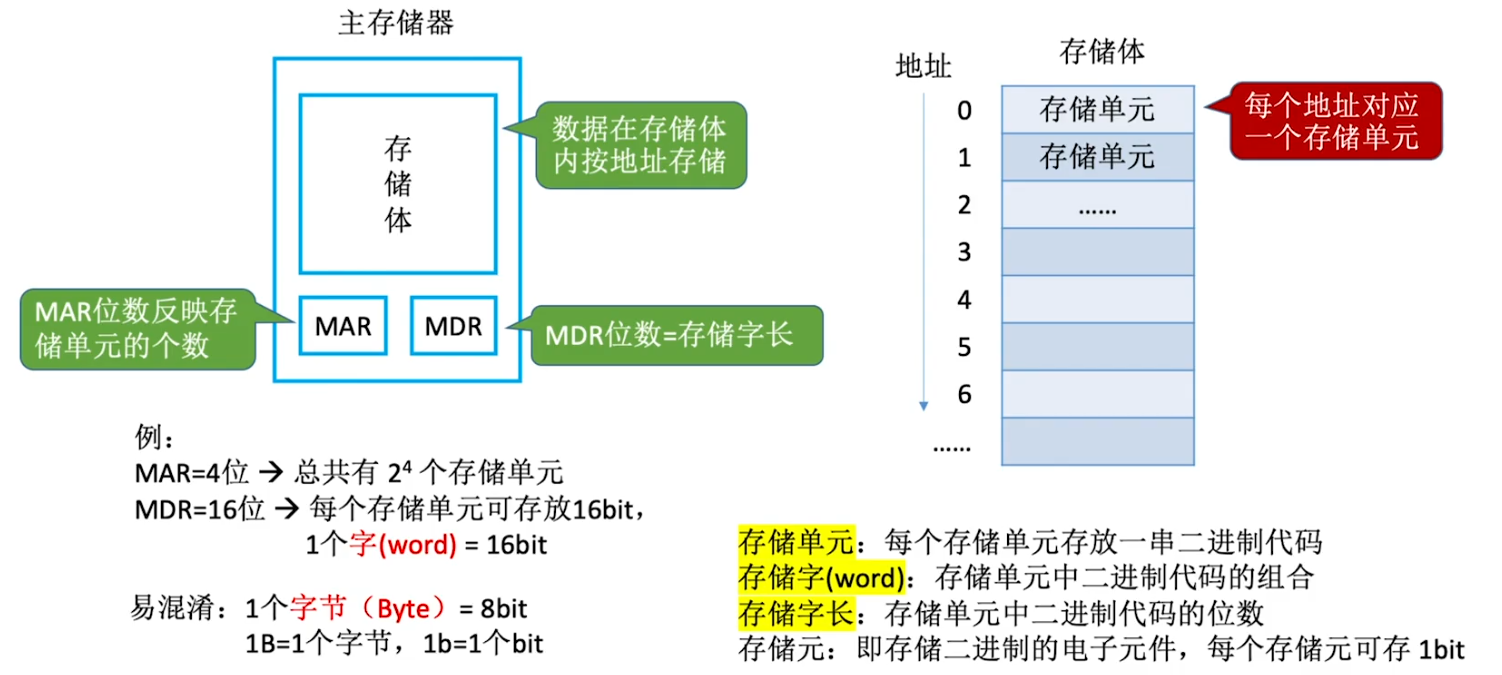
主存储器的基本组成
运算器的基本组成
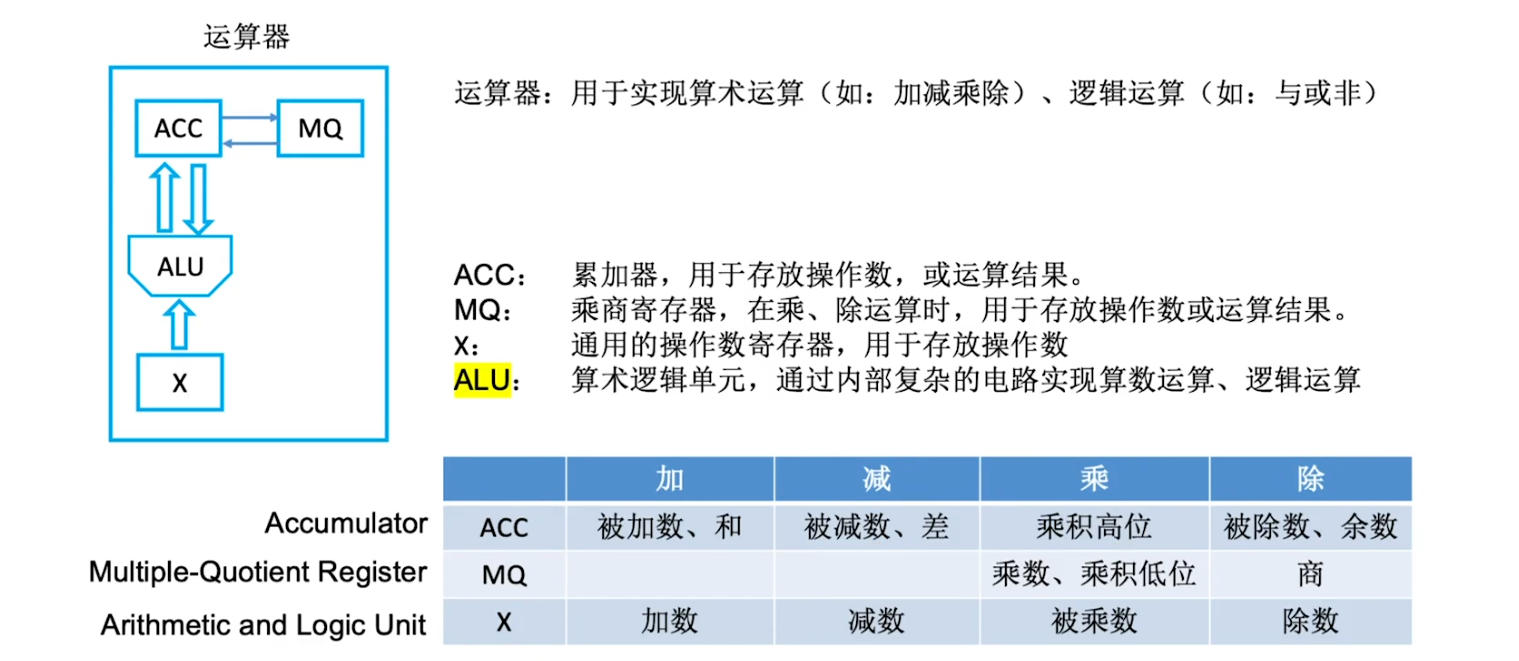
控制器的基本组成

- 完成一条指令:
- 取指
- 取指令 PC
- 分析指令 IR
- 执行
- 执行指令 CU
计算机的工作过程
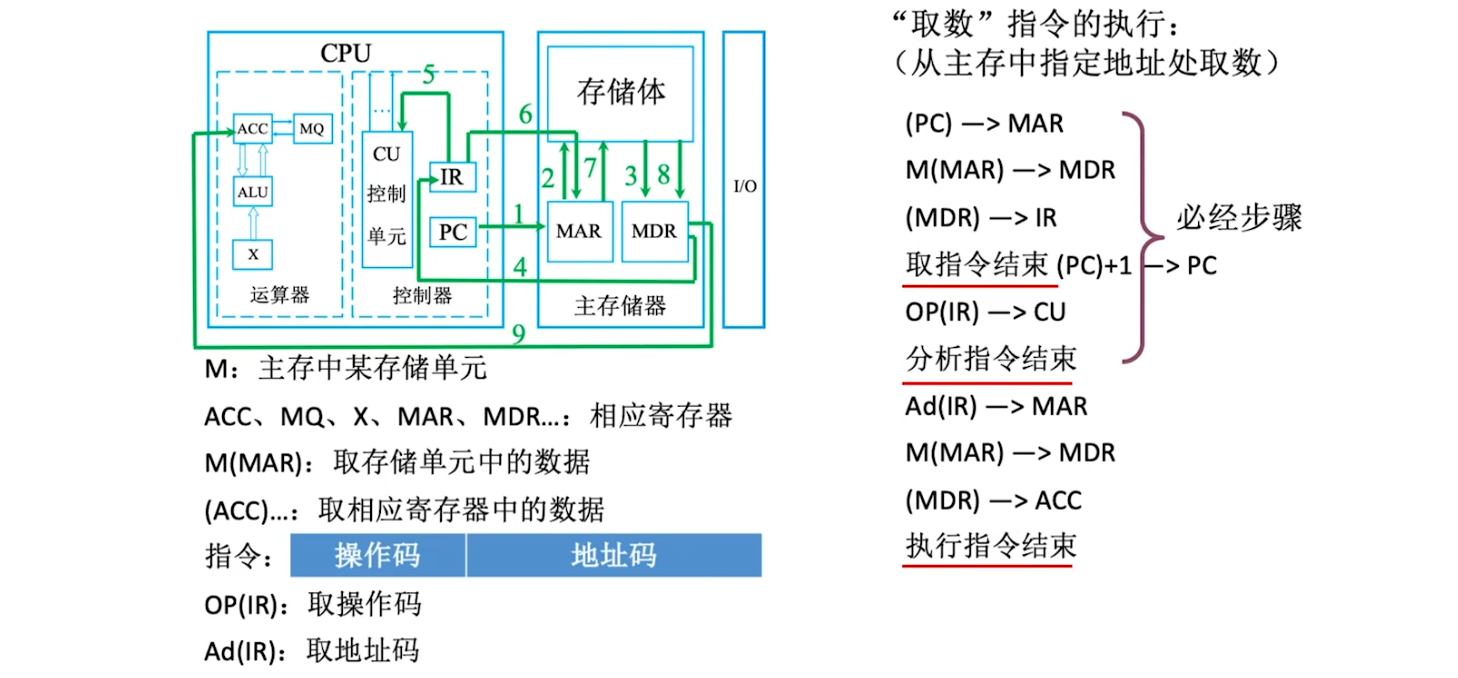
执行指令阶段: 不同的指令具体步骤不同cpu 区分指令和数据的依据: 指令周期的不同阶段现在的计算机通常把 MAR 、 MDR 也集成在 CPU 内
计算机系统的多级层次结构
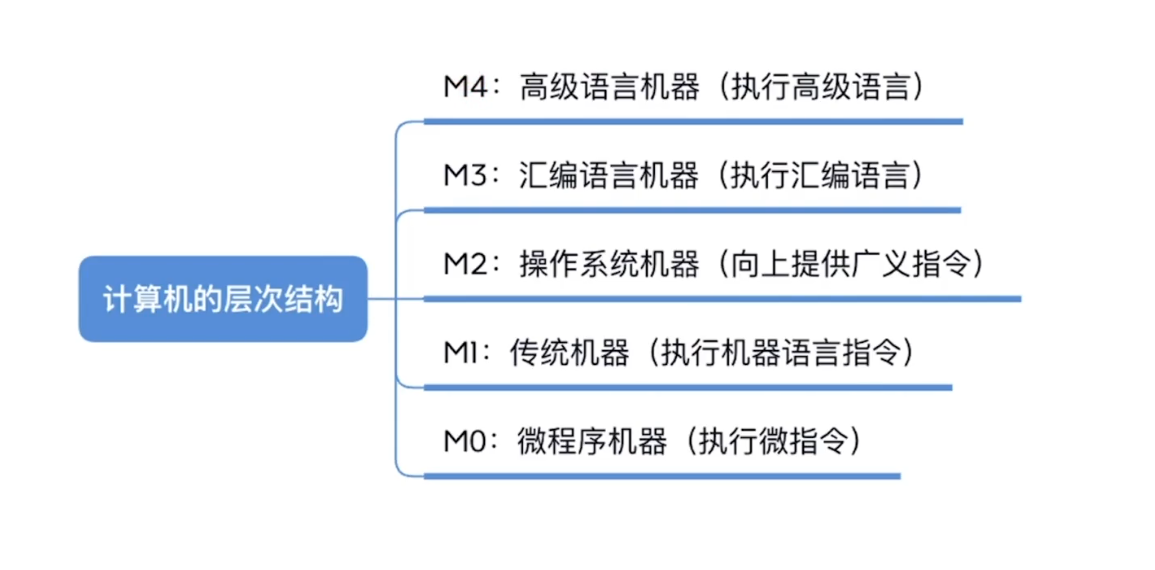
计算机的层次结构
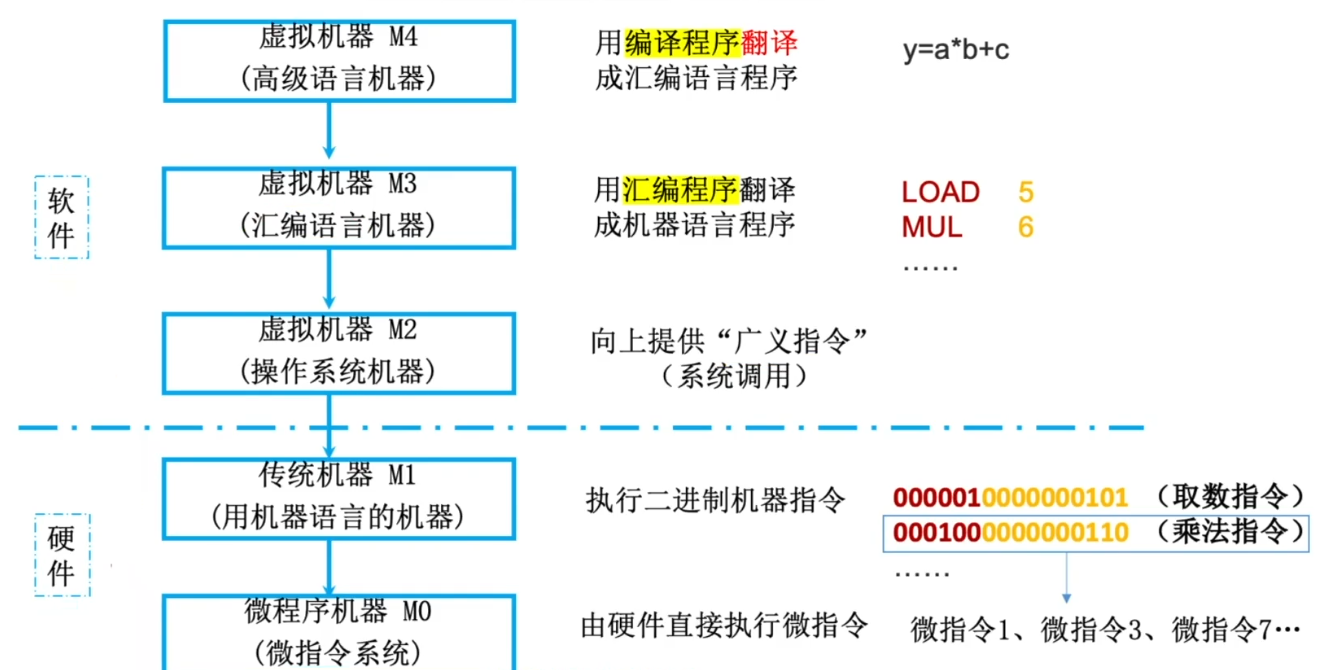
- 下层是上层的基础,上层是下层的扩展
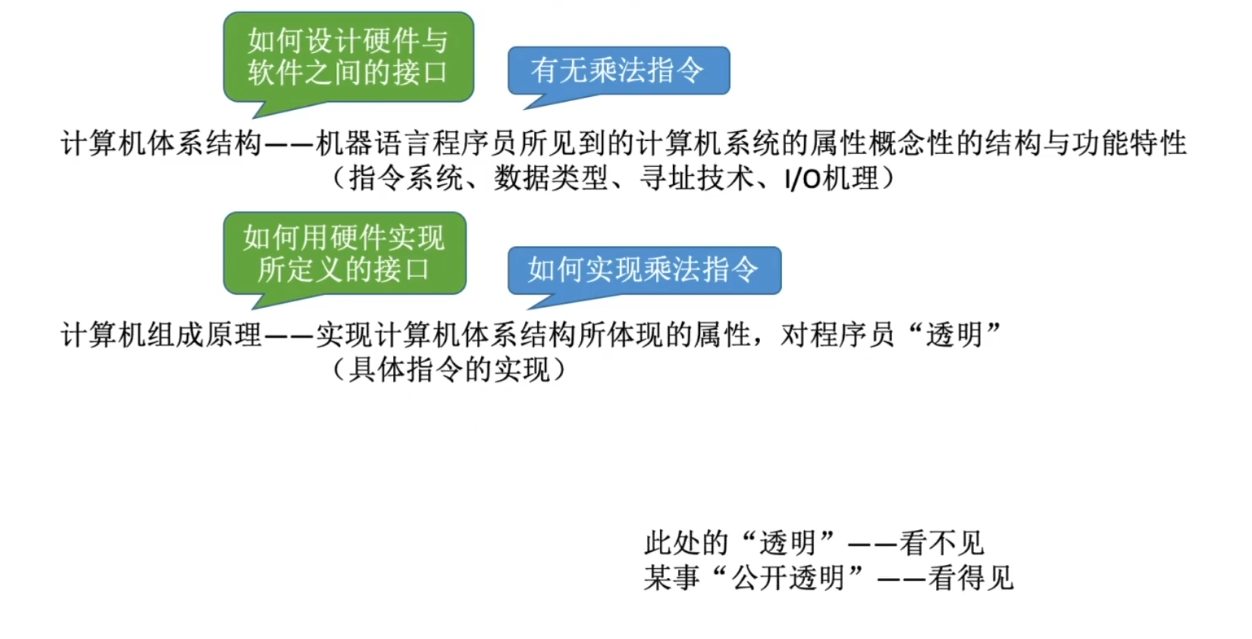
计算机体系结构 vs 计算机组成原理
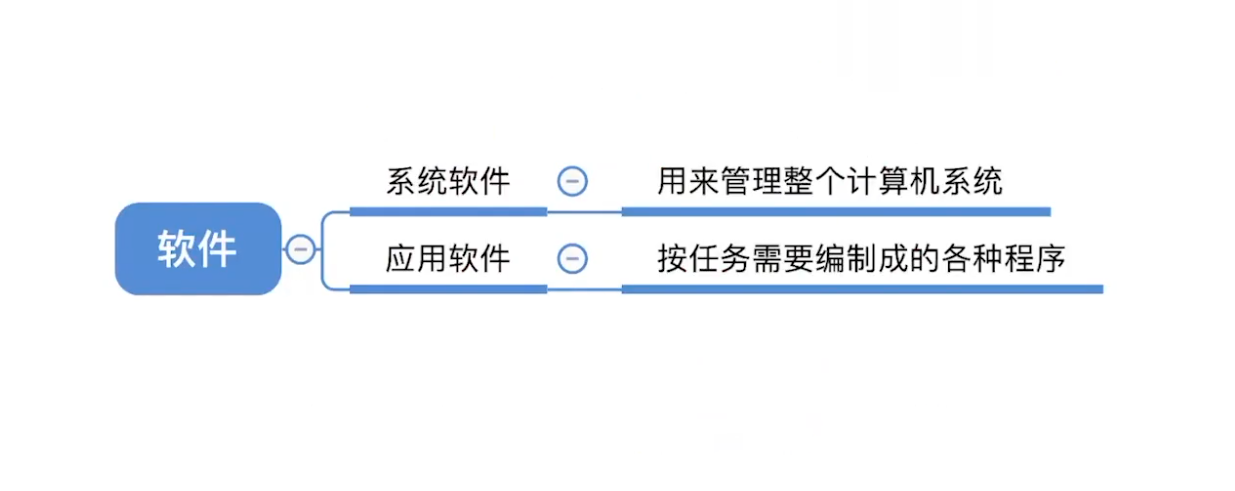
计算机软件
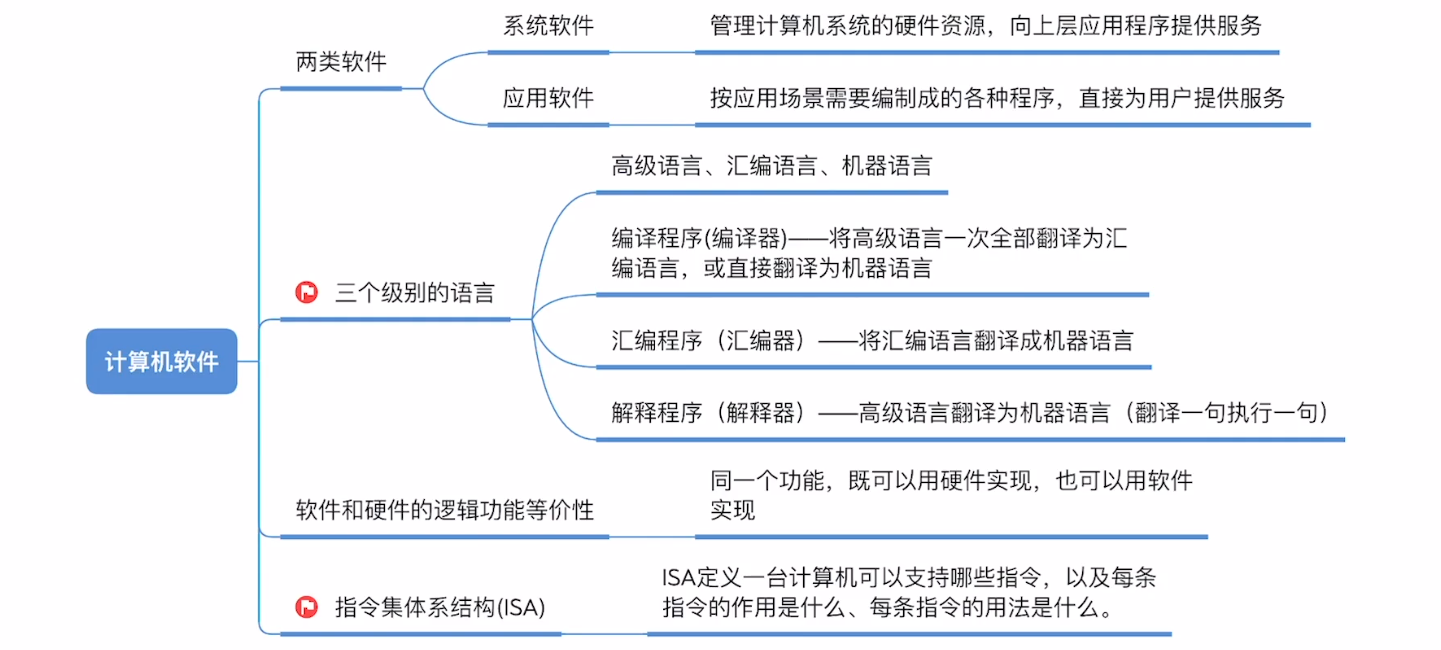
系统软件和应用软件
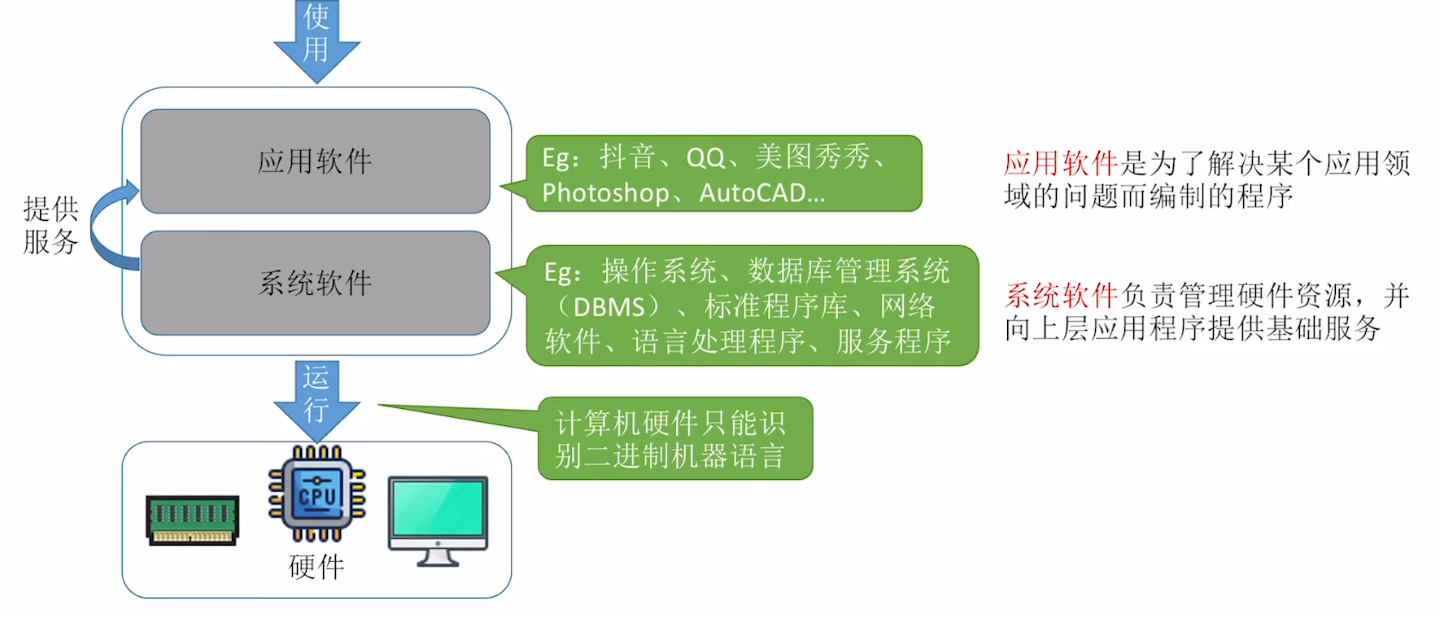
三种级别的语言
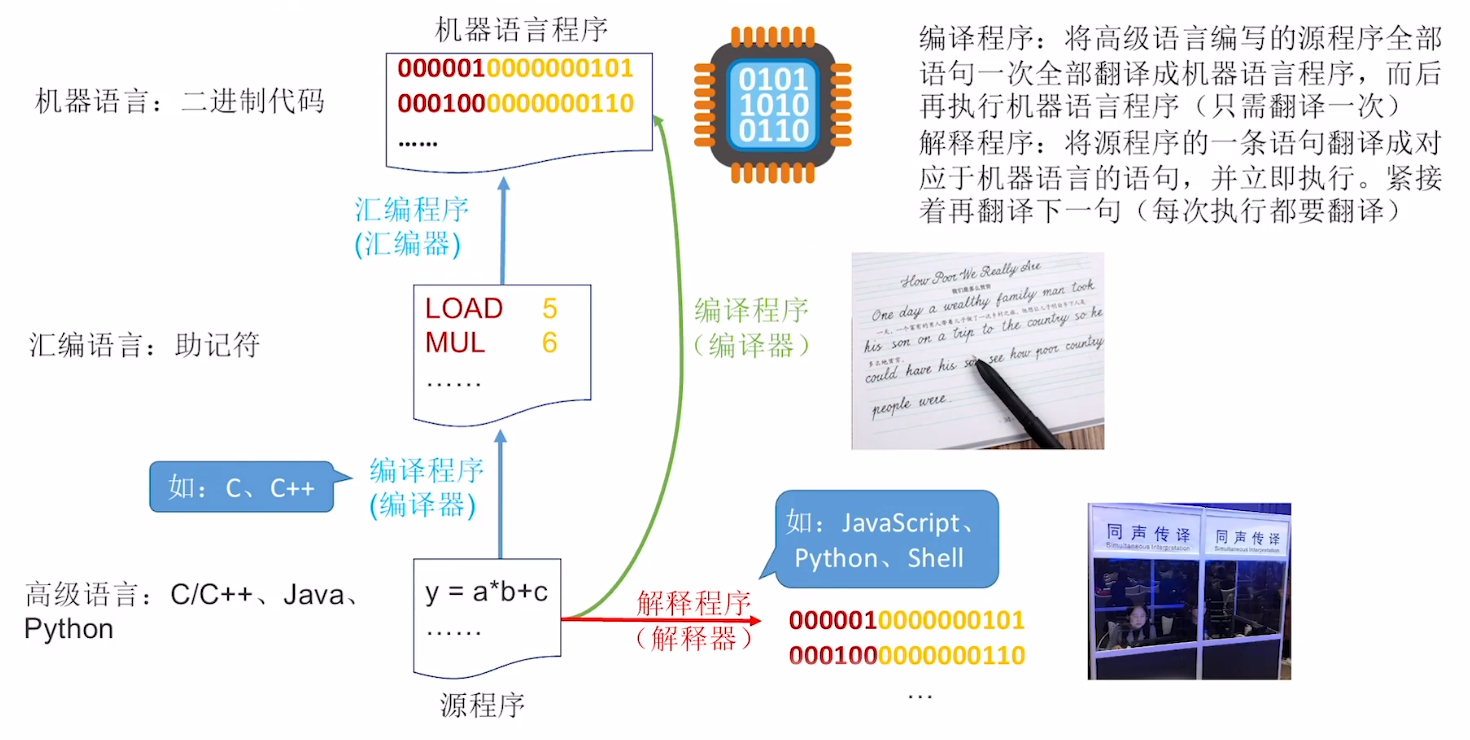
- 编译器 、 汇编器 、 解释器 , 可统称 “ 翻译程序 ”
软件和硬件的逻辑功能等价性
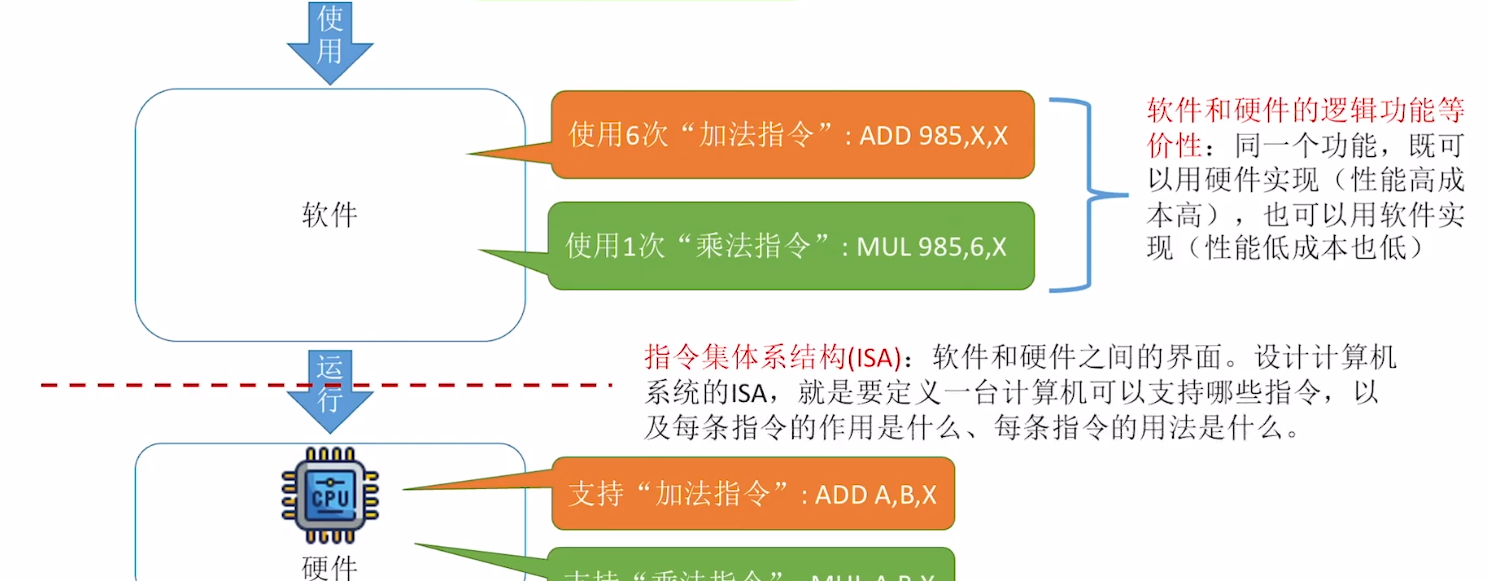
- 同一个功能 , 既可以用硬件实现 ( 性能高成本高 ) , 也可以用软件实现 ( 性能低成本也低 )
- 指令集体系结构(ISA):软件和硬件之间的界面。设计计算机系统的ISA,就是要定义一台计算机可以支持哪些指令,以及每条指令的作用是什么、每条指令的用法是什么。
计算机系统的工作原理
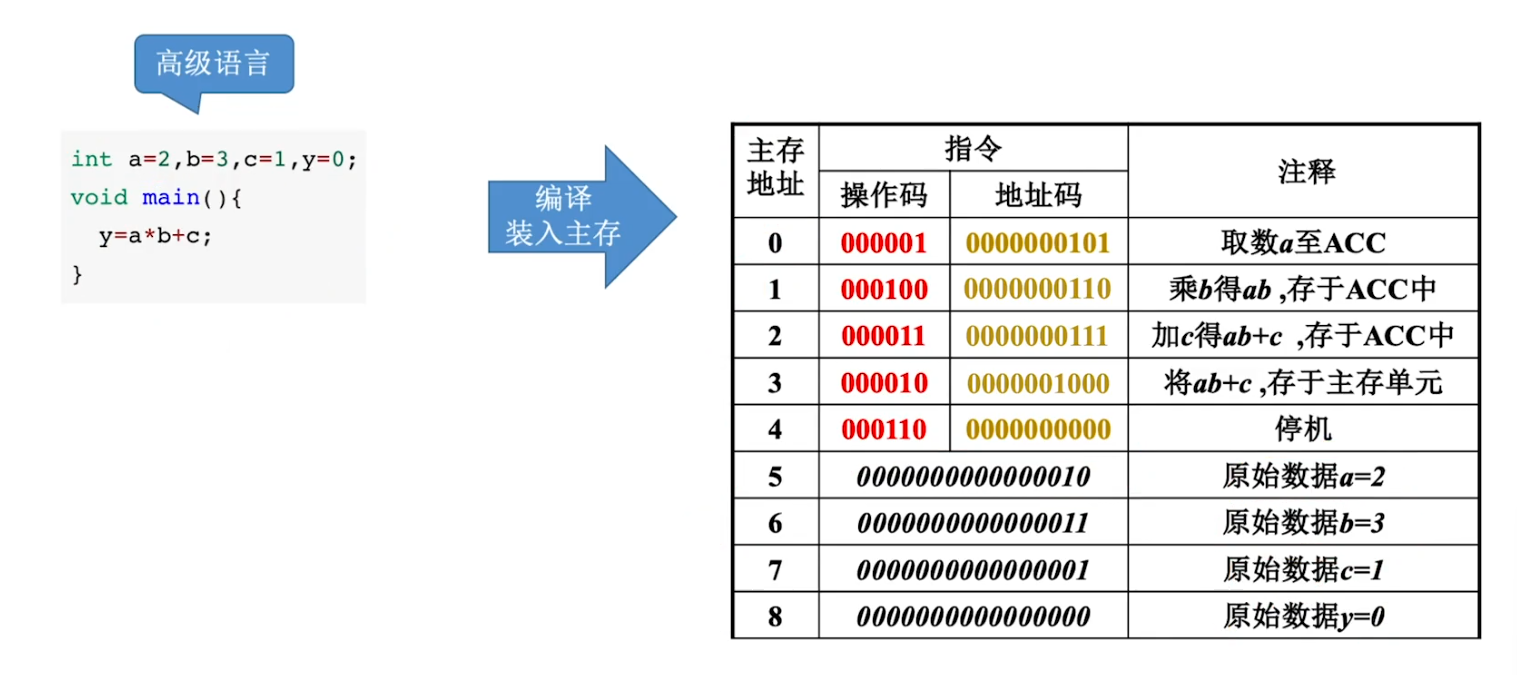
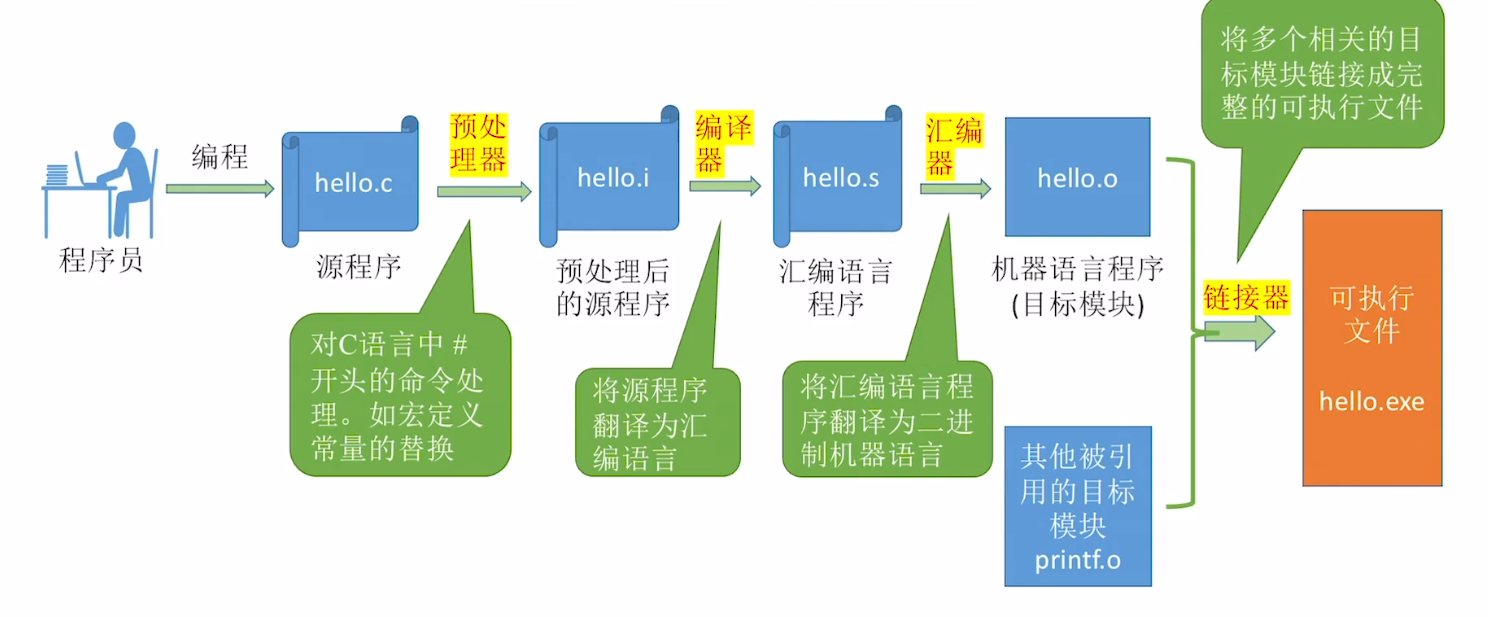
从 c 语言源程序到可执行文件
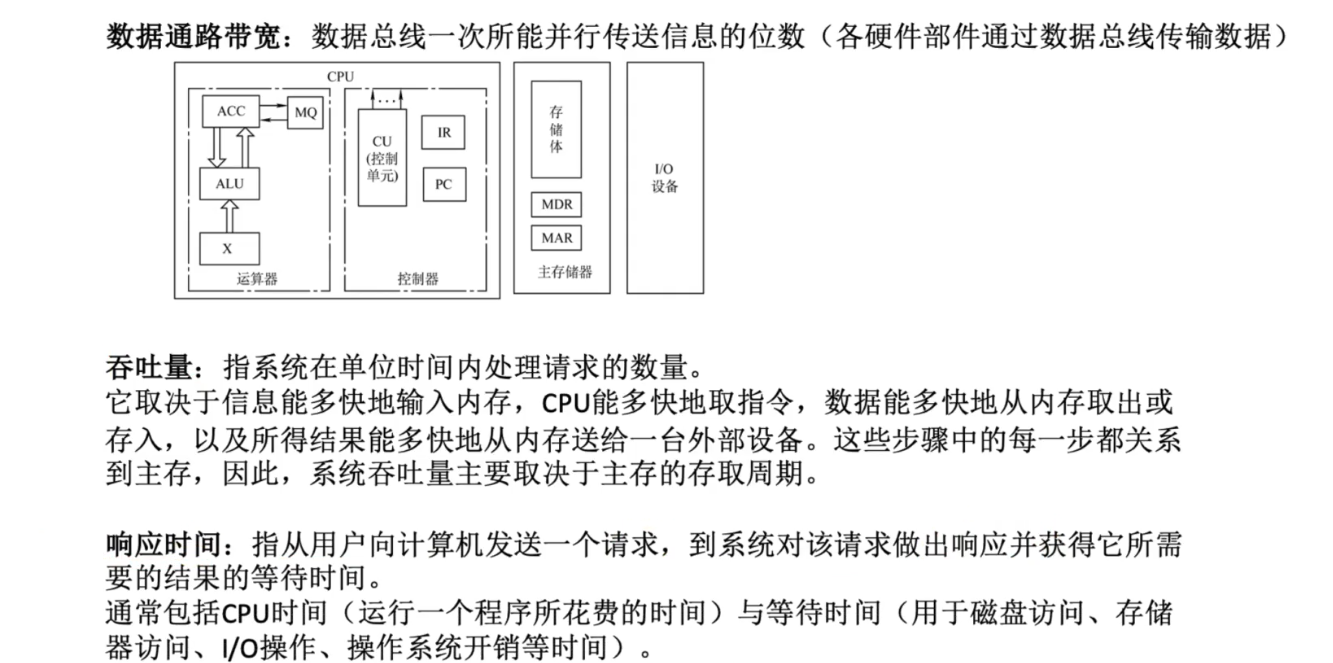
计算机的性能指标
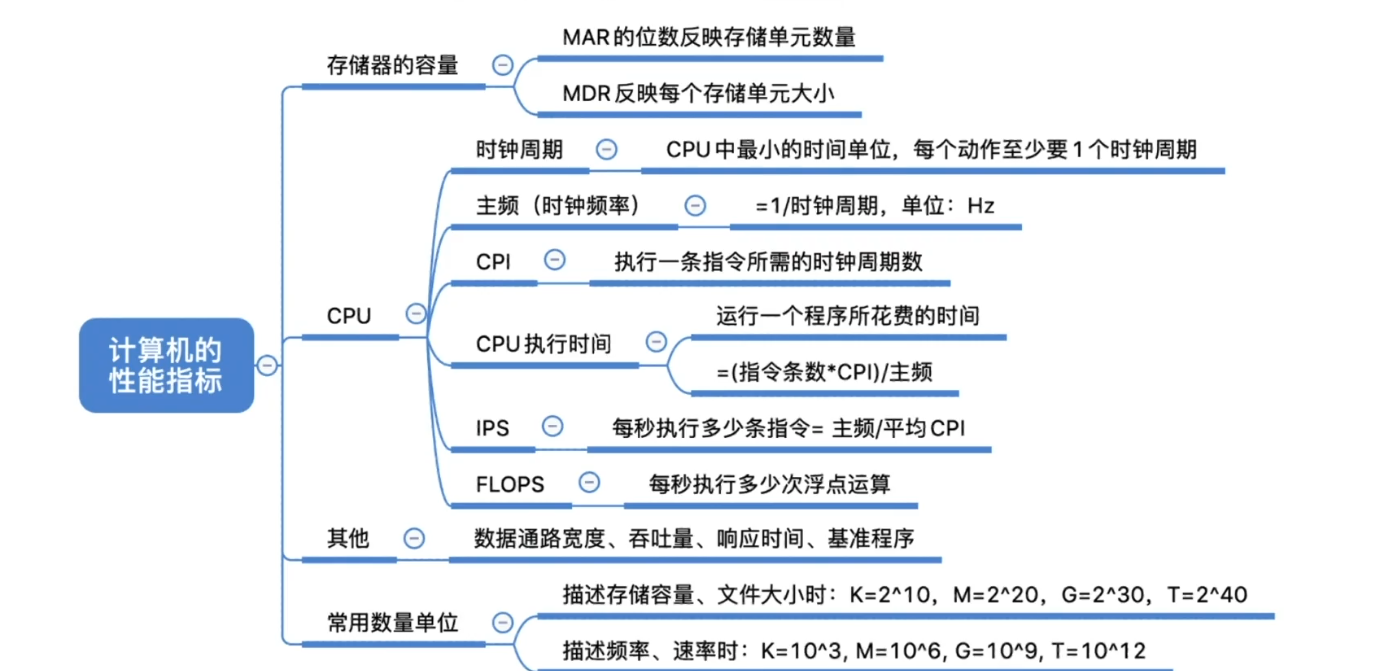
- 描述频率 、 速率时: K -> M-> G -> T -> P -> E -> Z
(10^3递增, K= 10^3)
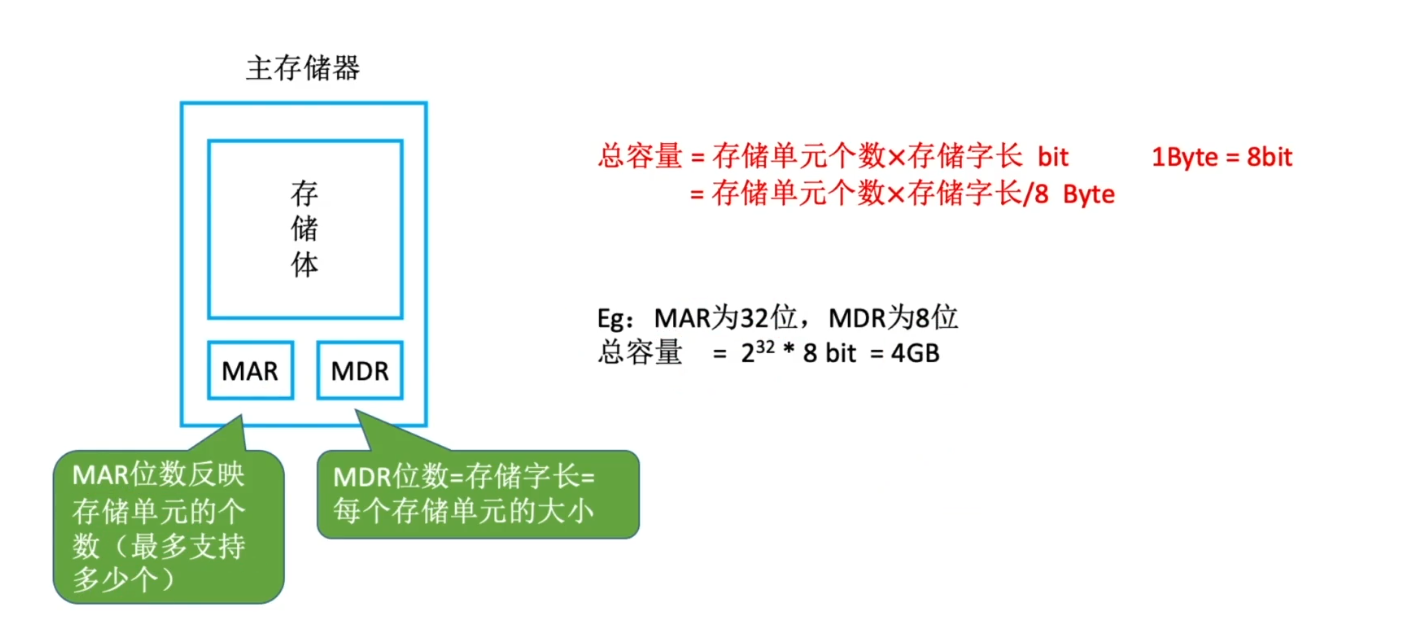
存储器的性能指标
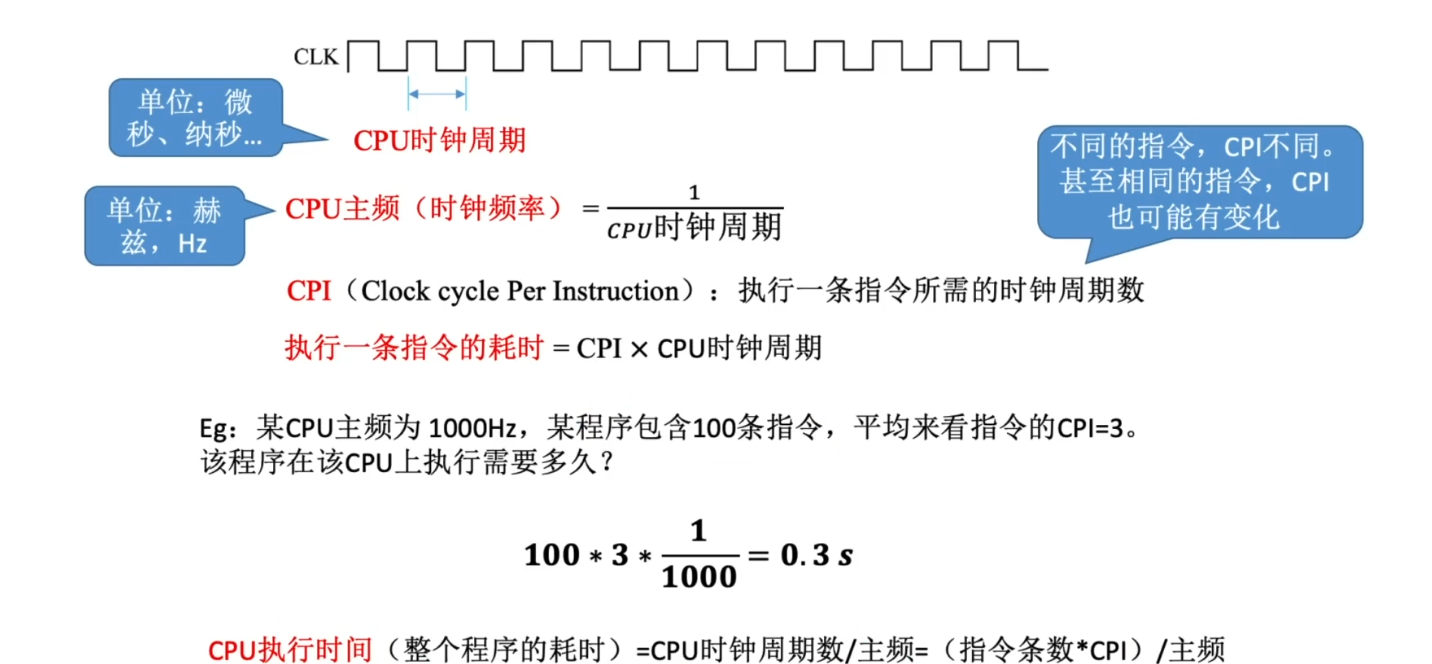
CPU的性能指标
- CPU 主频 : CPU 内数字脉冲信号振荡的频率

系统整体的性能指标
动态测试
基准程序是用来测量计算机处理速度的一种实用程序,以便于被测量的计算机性能可以与运行相同程序的其它计算机性能进行比较。
主频高的CPU一定比主频低的CPU快吗?
- 不一定,如两个CPU,A的主频为2GHz,平均CPI=10;B的主频1GHz,平均CPI=1…
若A、B两个CPU的平均CPI相同,那么A一定更快吗?
- 也不一定,还要看指令系统,如 A不支持乘法指令,只能用多次加法实现乘法;而B支持乘法指令。
基准程序执行得越快说明机器性能越好吗?
- 基准程序中的语句存在频度差异,运行结果也不能完全说明问题
数据的表示和运算
进位计数制
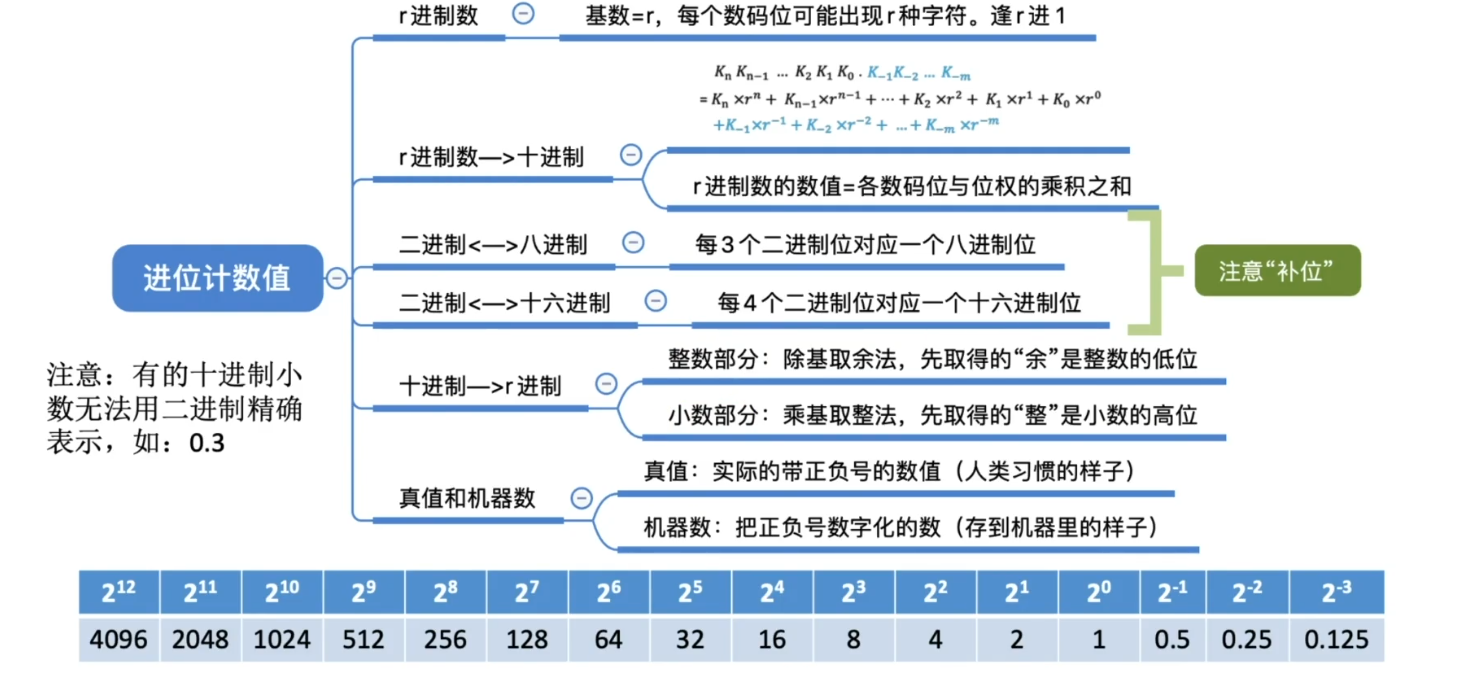
r进制计数法

任意进制 -> 十进制

二进制 <-> 八进制十进制

各种进制常见书写方式

十进制 -> 任意进制
整数部分: 除基取余
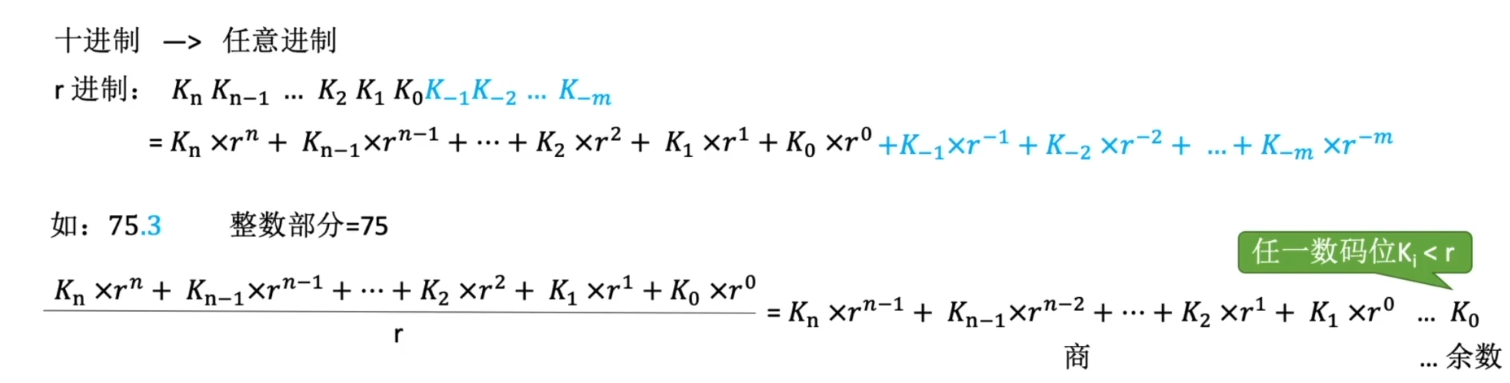
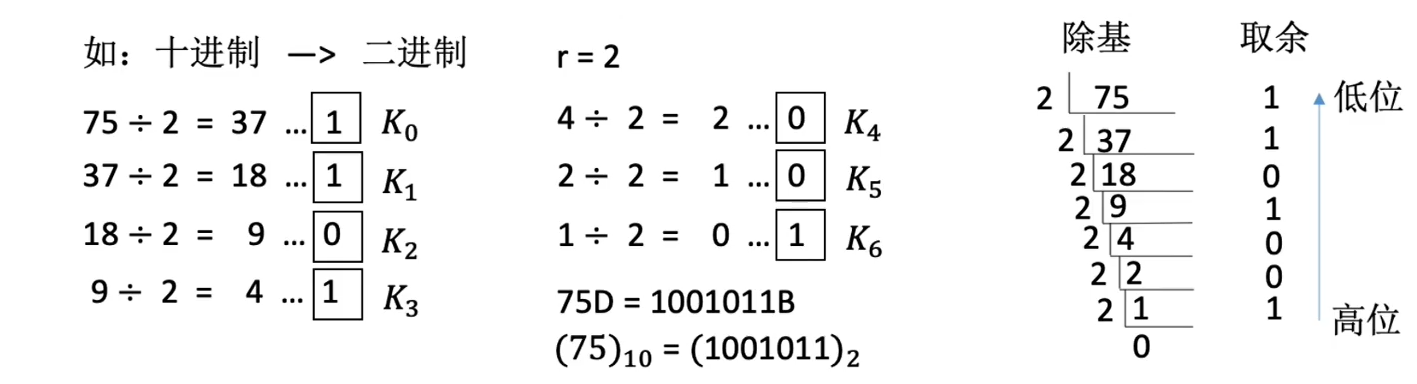
小数部分: 乘基取整


十进制 -> 二进制 (拼凑法)
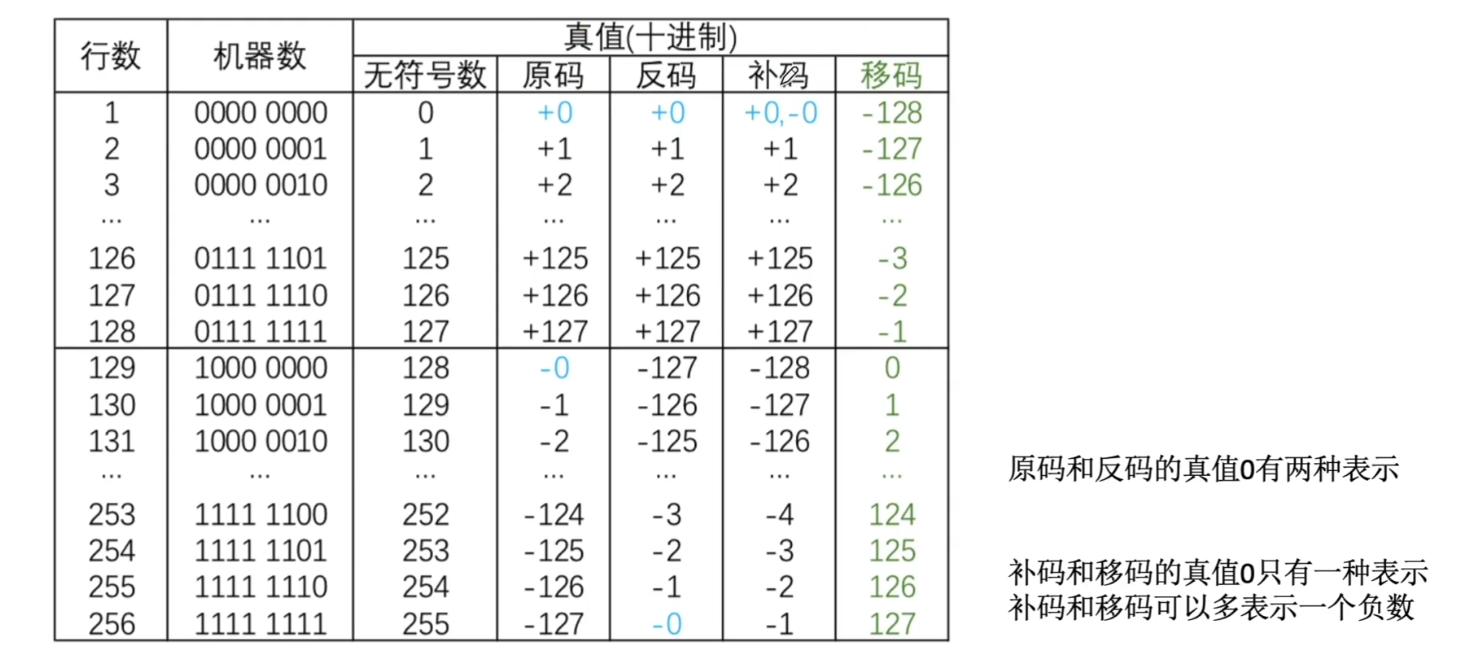
真值和机器数

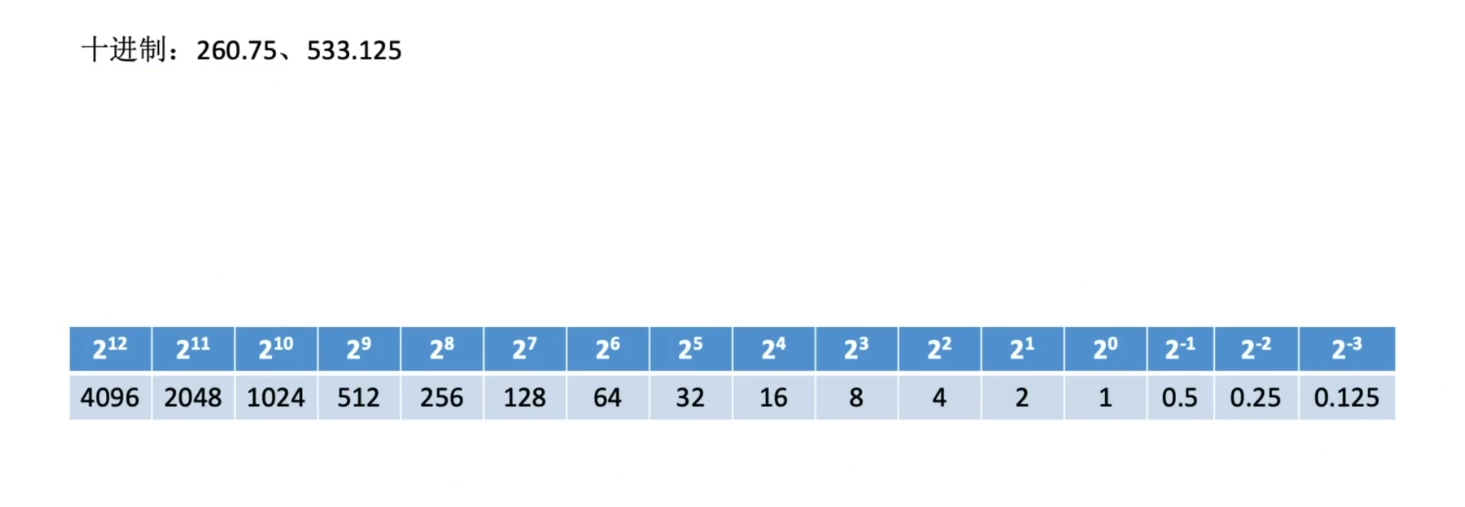
定点数的表示

无符号数的定点表示

- 通常只有无符号整数, 没有无符号小数
有符号数的定点表示
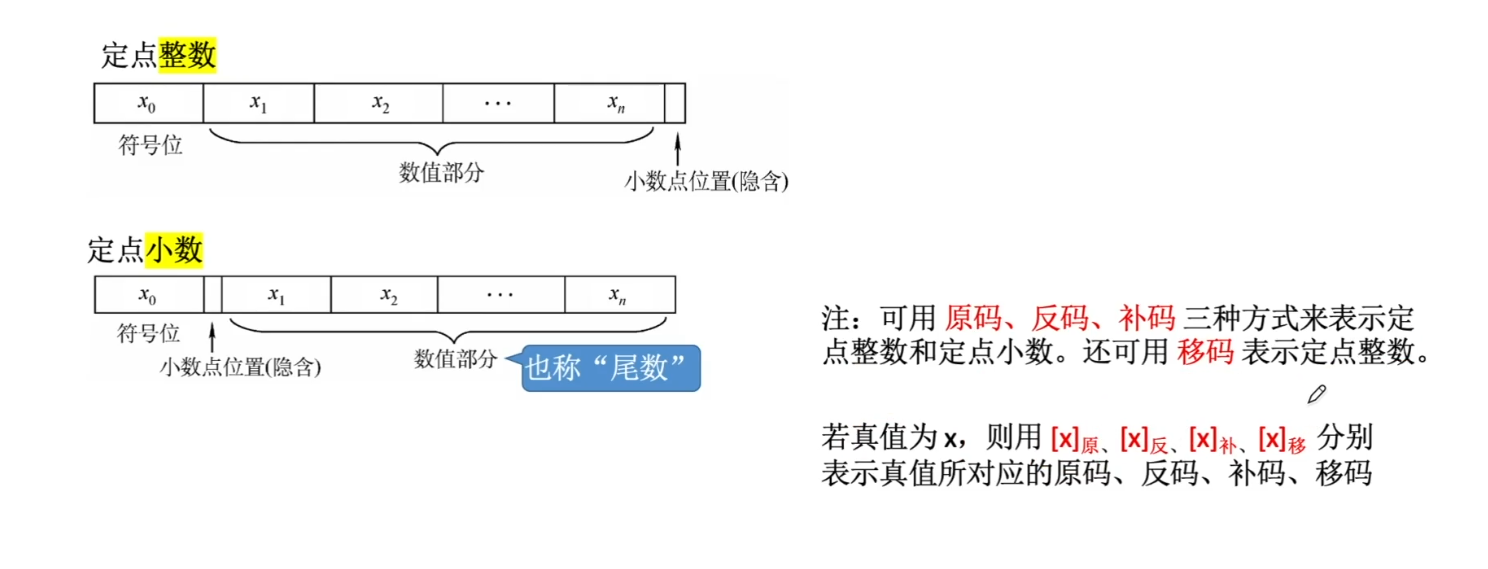
原码
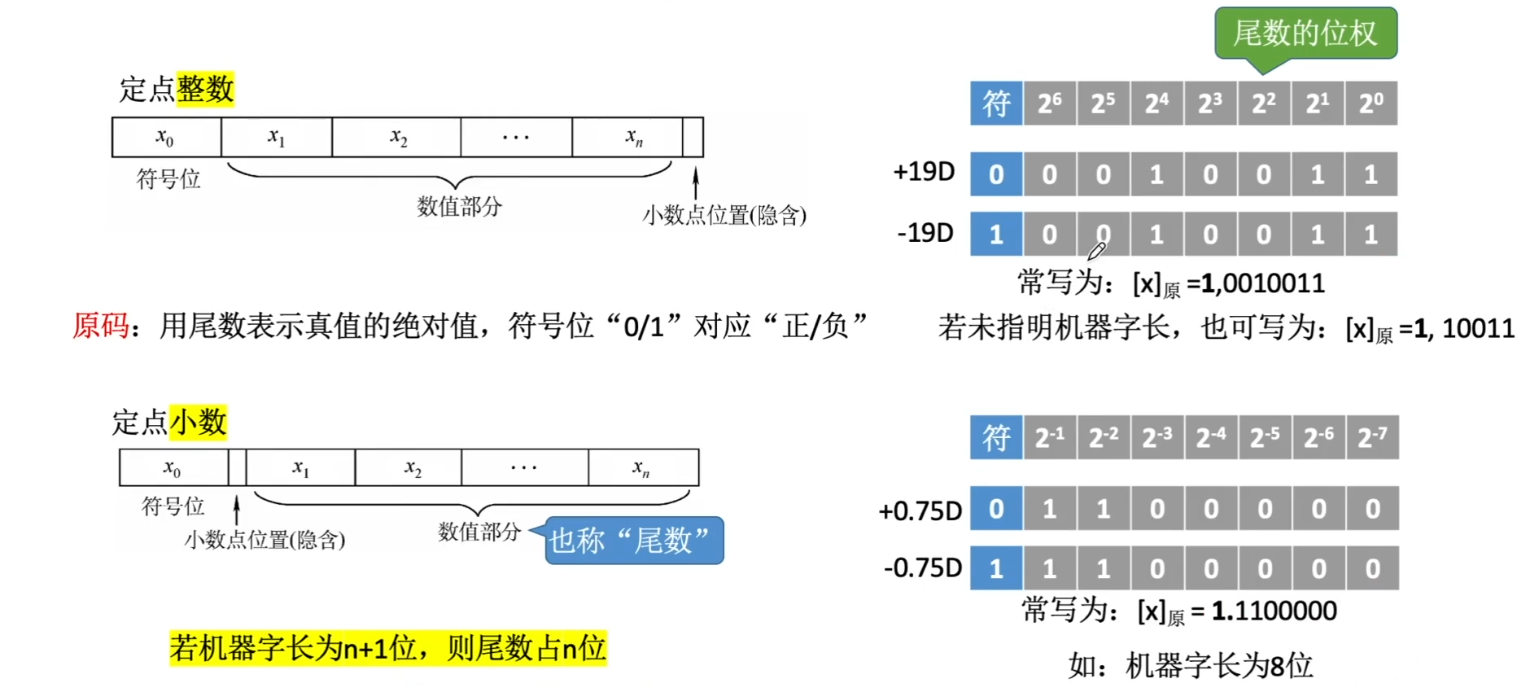
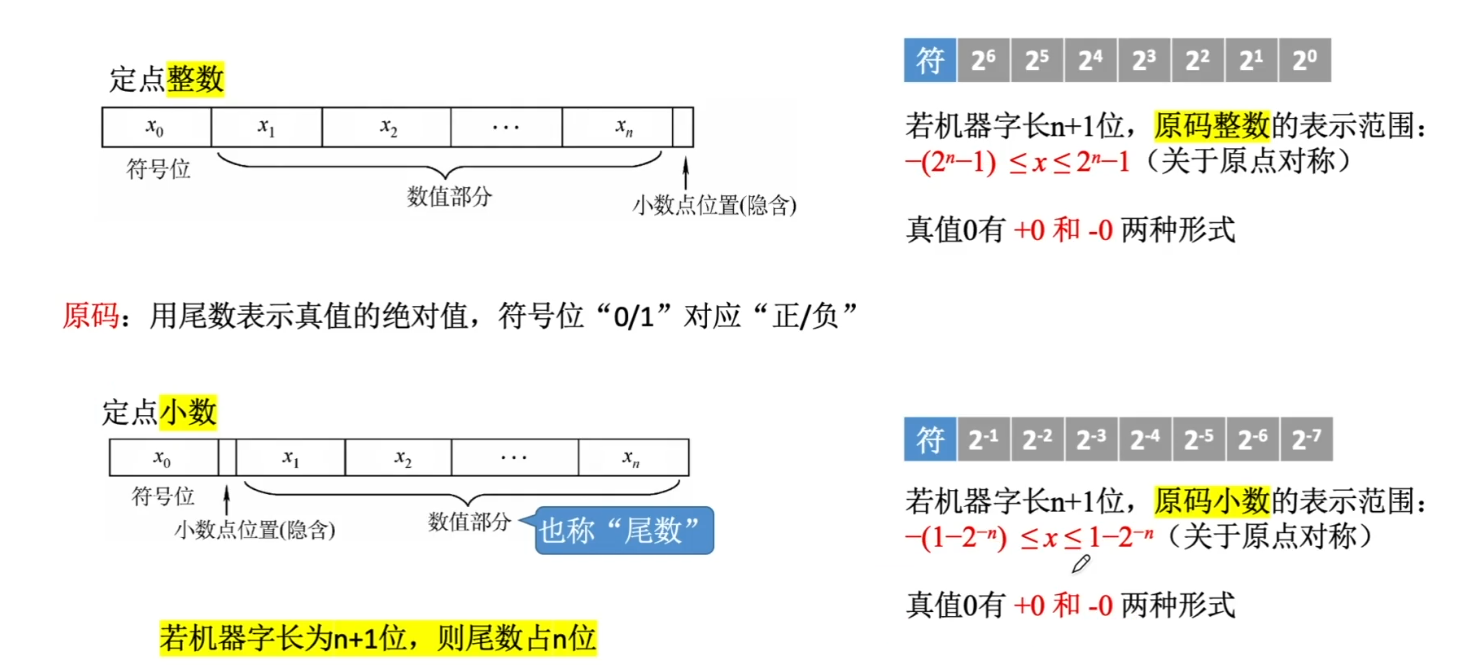
反码

补码

移码


练习

数据的机器级表示
补码
- 有符号数才称补码,无符号数没有补码
- 对于有符号数,最高位为1,就是负数,最高位为0,就是正数
补码是对原码取反后加1的结果补码变原码依然是取反加1- 计算机的 CPU 无法做减法操作(硬件上没有减法器),只能做加法操作
- 计算机所做的减法,都是通过加法器将其变化为加法实现的
- 由于是X86架构是小端存储,小端存储是低字节在前,高字节在后
- 即低字节在低地址,高字节在高地址,大端和小端则相反
- 注意,通过8位表示, -5的补码是 1111 1011 , -5的原码是 1000 0101 ,
符号位是不动的,只有值的部分是 5
1 |
|
1 | k=-3 |
反码
- 反码是一种在计算机中数的机器码表示
正数的反码和原码一样负数的反码就是在原码的基础上符号位保持不变,其它位取反
| 十进制 | 原码 | 反码 |
|---|---|---|
| 6 | 0000 0110 | 0000 0110 |
| -3 | 1000 0011 | 1111 1100 |
整形溢出解析
- 不同整型变量表示的整型数的范围不同,超出范围会发生溢出现象,导致计算出错
1 |
|
1 | -32768 |
浮点数 IEEE754 标准
float |
||
| 符号位 | 指数部分 | 小数部分 |
0 |
8位 |
23位 |
double |
||
| 符号位 | 指数部分 | 小数部分 |
0 |
11位 |
52位 |
- 浮点型数据是按照
指数形式存储的 - 系统把一个浮点型数据分成小数部分(用 M 表示)和指数部分(用 E 表示)并分别存放。
- 指数部分采用规范化的指数形式,指数也分正、负(符号位,用 S 表示)
例如:
| 格式 | SEEEEEEE | EMMMMMMM | MMMMMMMM | MMMMMMMM |
|---|---|---|---|---|
| 二进制数 | 01000000 | 10010000 | 00000000 | 00000000 |
| 十六进制数 | 40 | 90 | 00 | 00 |
S:S 是符号位,用来表示正、负,是 1 时代表负数,是 0 时代表正数E:E 代表指数部分指数部分的值规定只能是 1 到 254,不能是全 0,全 1指数部分运算前都要减去 127(这是 IEEE-754 的规定),因为还要表示负指数- 这里的 10000001 转换为十进制数为 129,129 − 127 = 2,即实际指数部分为 2
M:M 代表小数部分- 这里为 0010 0000 0000 0000 0000 000
底数左边省略存储了一个1(这是 IEEE-754 的规定),使用的实际底数表示为 1.0010 0000 0000 0000 0000 000
等价于
| S | 阶码 | 尾数 |
|---|---|---|
| 0 | 10000001 | 0010 0000 0000 0000 0000 000 |
1 |
|
1 | f = 4.500000 |
浮点数精度丢失
- 针对强制类型转换,
int转float可能造成精度丢失,因为 int 是有 10 位有效数字的 int转为double不会造成精度丢失,float转为double也不会丢失精度
1 |
|
1 | b=12345678848.000000 |
汇编语言
汇编指令格式
CPU 是如何执行我们的程序的?
- 我们编译后的可执行程序, 也就是 main.exe, 是放在
代码段的 - 读取了代码段的某一条指令后, 会交给译码器来解析
- 这时候译码器就知道要做什么事情了
- CPU 中的计算单元
加法器不能直接对栈上的某个变量, 直接做加 1 操作的 - 需要首先将栈, 也就是内存上的数据, 加载到寄存器中
- 然后再用加法器做加 1 操作, 再从寄存器搬到内存上去
- 我们编译后的可执行程序, 也就是 main.exe, 是放在
CPU 读写寄存器的速度比读写内存的速度要快很多!指令地址是由
程序计数器(PC)给出,PC存放当前欲执行指令的地址, 而指令的地址码字段则保存的操作数的地址
操作码字段:表征指令的操作特性与功能(指令的唯一标识), 不同的指令操作码不能相同地址码字段:指定参与操作的操作数的地址码指令中指定操作数存储位置的字段称为地址码, 地址码中可以包含存储器地址, 也可包含寄存器编号
指令中可以有
一个、两个或者三个操作数, 也可没有操作数根据一条指令有几个操作数地址, 可将指令分为
零地址指令、一地址指令、二地址指令、三地址指令、四地址指令零地址指令: 只有操作码, 没有地址码(空操作 停止等)
一地址指令: 指令编码中只有一个地址码, 指出了参加操作的一个操作数的存储位置, 如果还有另一个操作数则隐含在累加器中
二地址指令: 指令编码中有两个地址, 分别指出了参加操作的两个操作数的存储位置, 结果存储在其中一个地址中
二地址指令格式中, 从操作数的物理位置来说有可归为三种类型
寄存器-寄存器(RR)型指令: 需要多个通用寄存器或个别专用寄存器, 从寄存器中取操作数, 把操作结果放入另一个寄存器, 机器执行寄存器-寄存器型的指令非常快, 不需要访存。寄存器-存储器(RS)型指令: 执行此类指令时, 既要访问内存单元, 又要访问寄存器。存储器-存储器(SS)型指令: 操作时都是涉及内存单元, 参与操作的数都是放在内存里, 从内存某单元中取操作数, 操作结果存放至内存另一单元中, 因此机器执行指令需要多次访问内存。
三地址指令: 指令编码中有三个地址码, 指出了参加操作的两个操作数的存储位置和一个结果的地址
复杂指令集: 变长 x86 CISC Complex Instruction Set Computer精简指令集: 等长 arm RISC Reduced Instruction Set Computin
生成汇编的方法
- 编译过程
main.c—>编译器—>main.s文件(.s 文件就是汇编文件, 文件内是汇编代码)main.s汇编文件—>汇编器—>main.objmain.obj文件—>链接器—>可执行文件
1 | gcc -S -fverbose-asm main.c |
1 | gcc -m32 -masm=intel -S -fverbose-asm main.c |
相关寄存器
- EBP 堆栈基指针 (Base Pomter)
- ESP 堆栈顶指针 (Stack Pomter)
- …
- 除
EBP和ESP外, 其他几个寄存器的用途是比较任意的, 也就是什么都可以存。
汇编常用指令
汇编指令通常可以分为
数据传送指令、逻辑计算指令和控制流指令下面以
Intel格式为例, 介绍一些重要的指令以下用于操作数的标记分别表示寄存器、内存和常数。
<reg>: 表示任意寄存器, 若其后带有数字, 则指定其位数- <reg32>表示 32 位寄存器(eax、ebx、ecx、edx、esi、edi、esp 或 ebp)
- <reg16>表示 16 位寄存器(ax、bx、cx 或 dx)
- <reg8>表示 8 位寄存器(ah、al、bh、bl、ch、cl、dh、dl)
<mem>: 表示内存地址(如[eax]、[var+4]或dword ptr [eax+ebx])<con>: 表示 8 位、16 位或 32 位常数- <con8>表示 8 位常数
- <con16>表示 16 位常数
- <con32>表示 32 位常数。(也称为
立即数)
数据传送指令
mov 指令: 将第二个操作数(寄存器的内容、内存中的内容或常数值)复制到第一个操作数(寄存器或内存)。但不能用于直接从内存复制到内存。
1
mov eax ebx # 将 ebx 值复制到 eax
push 指令: 将操作数压入内存的栈, 常用于函数调用。ESP 是栈顶, 压栈前先将ESP 值减 4(栈增长方向与内存地址增长方向相反), 然后将操作数压入 ESP 指示的地址。
- 注意, 栈中元素固定为 32 位
pop 指令: 与 push 指令相反, pop 指令执行的是出栈工作, 出栈前先将 ESP 指示的地址中的内容出栈, 然后将 ESP 值加 4。
算术和逻辑运算指令
add/sub 指令: add 指令将两个操作数相加, 相加的结果保存到第一个操作数中。sub指令用于两个操作数相减, 相减的结果保存到第一个操作数中。
1
sub exa 10 # eax <--- eax-10
inc/dec 指令: inc、dec 指令分别表示将操作数自加 1、自减 1。
imul 指令: 带符号整数乘法指令, 有两种格式:
- 两个操作数, 将两个操作数相乘, 将结果保存在第一个操作数中,
第一个操作数必须为寄存器 - 三个操作数, 将第二个和第三个操作数相乘, 将结果保存在第一个操作数中,
第一个操作数必须为寄存器 - 乘法操作结果可能溢出, 则编译器置溢出标志 OF = 1, 以使 CPU 调出溢出异常处理程序。
- 两个操作数, 将两个操作数相乘, 将结果保存在第一个操作数中,
idiv 指令: 带符号整数除法指令, 它
只有一个操作数, 即除数, 而被除数则为 edx:eax中的内容(64 位整数), 操作结果有两部分: 商和余数, 商送到 eax, 余数则送到edx。and/or/xor 指令。and、or、xor 指令分别是
按位与、按位或、按位异或操作指令, 用于操作数的位操作(按位与, 按位或, 异或),操作结果放在第一个操作数中not 指令: 位翻转指令, 将操作数中的每一位翻转, 即 0→1、1→0。
neg 指令: 取负指令。
shl/shr 指令: 逻辑移位指令, shl 为逻辑左移, shr 为逻辑右移, 第一个操作数表示被操作数, 第二个操作数指示移位的位数。
lea 指令: 地址传送指令, 将有效地址传送到指定的的寄存器。
控制流指令
控制PC指针去哪里- x86 处理器维持着一个指示当前执行指令的指令指针(IP),
当一条指令执行后, 此指针自动指向下一条指令- IP 寄存器不能直接操作, 但可以用控制流指令更新
- 通常用标签(label)指示程序中的指令地址, 在 x86 汇编代码中, 可在任何指令前加入标签
jmp 指令: jmp 指令控制 IP 转移到 label 所指示的地址(从 label 中取出指令执行)。
jcondition 指令:
条件转移指令, 依据 CPU 状态字中的一系列条件状态转移。CPU状态字中包括指示最后一个算术运算结果是否为 0, 运算结果是否为负数等je <label>(jump when equal)jne <label>(jump when not equal)jz <label>(jump when last result was zero)jg <label>(jump when greater than)jge <label>(jump when greater than or equal to)jl <label>(jump when less than)jle <label>(jump when less than or equal to)
cmp/test 指令: cmp 指令用于
比较两个操作数的值, test 指令对两个操作数进行逐位与运算,这两类指令都不保存操作结果, 仅根据运算结果设置 CPU 状态字中的条件码。call/ret 指令: 分别用于实现子程序(过程、函数等)的调用及返回。
- call 指令首先将当前执行指令地址入栈, 然后无条件转移到由标签指示的指令
- 与其他简单的跳转指令不同, call 指令保存调用之前的地址信息(当 call 指令结束后, 返回调用之前的地址)
- ret 指令实现子程序的返回机制, ret 指令弹出栈中保存的指令地址, 然后无条件转移到保存的指令地址执行
- call 和 ret 是程序(函数)调用中最关键的两条指令。
条件码
编译器通过条件码(标志位)设置指令和各类转移指令来实现程序中的选择结构语句。
除了整数寄存器, CPU 还维护着一组
条件码(标志位)寄存器, 它们描述了最近的算术或逻辑运算操作的属性。可以检测这些寄存器来执行条件分支指令CF:进(借)位标志。最近无符号整数加(减)运算后的进(借)位情况。有进(借)位, CF=1;否则 CF=0。如 (unsigned) t < (unsigned) a ,因为判断大小是相减ZF:零标志。最近的操作的运算结算是否为 0。若结果为 0, ZF=1;否则 ZF=0SF:符号标志。最近的带符号数运算结果的符号。负数时, SF=1;否则 SF=0OF:溢出标志。最近带符号数运算的结果是否溢出,若溢出, OF=1;否则 OF=0OF 和 SF 对无符号数运算来说没有意义, 而 CF 对带符号数运算来说没有意义
如何判断溢出, 简单的就是正数相加变负数为溢出, 负数相加变正数溢出, 但是考研不这么考, 考研往往给你十六进制的两个数考溢出, 通过如下手法判断即可。
- 数据高位进位, 符号位未进位, 溢出。
- 数据位高位未进位, 符号位进位, 溢出。
- 数据位高位进位, 符号位进位, 不溢出。
- 数据位高位未进位, 符号位未进位, 不溢出。
数据位高位和符号位高位进位不一样的时候会溢出常见的算术逻辑运算指令(add、sub、imul、or、and、shl、inc、dec、not、sal 等)会设置条件码
但有
两类指令只设置条件码而不改变任何其他寄存器, 即 cmp 和 test 指令cmp指令和 sub 指令的行为一样, test 指令与 and 指令的行为一样, 但它们只设置条件码, 而不更新目的寄存器控制流指令中的 Jcondition 条件转移指令, 就是根据条件码 ZF 和 SF 来实现转跳。
乘法溢出后, 可以跳转到
溢出自陷指令例如 int 0x2e 就是一条自陷指令, 但是考研只需要掌握溢出, 可以跳转到
溢出自陷指令即可, 不需要记自陷指令有哪些。
变量赋值汇编
整型, 整型数组, 整型指针变量的赋值(浮点与字符等价的)
我们的 C 代码在让 CPU 去运行时, 其实所有的变量名都已经消失了, 实际是数据从一个空间, 拿到另一个空间的过程
我们访问所有变量的空间都是通过栈指针(esp)时刻都存着栈指针, 也可以称为栈顶指针的偏移, 来获取对应变量内存空间的数据的。
ptr – pointer (指针)的缩写
汇编里面 ptr 是规定的字 (保留字), 是用来临时指定类型的
可以理解为, ptr 是临时的类型转换, 相当于 C 语言中的强制类型转换intel 中的
dword ptr长字节(4 字节)word ptr双字节byte ptr一字节
1 |
|
1 | .file "main.c" |
选择循环汇编
- 字符串常量是存在文字常量区
1 |
|
1 | .file "main.c" |
如何得到机器码
1 | gcc -m32 -g -o main main.c |
1 | objdump --source main.exe >main.dump |
函数调用汇编
先必须明确的一点是,
函数栈是向下生长的向下生长, 是指从内存高地址向低地址的路径延伸栈有栈底和栈顶,
栈顶的地址要比栈底的低对 x86 体系的 CPU 而言, 寄存器
ebp可称为帧指针或基址指针(base pointer), 寄存器esp可称为栈指针(stack pointer)ebp 在未改变之前始终指向栈帧的开始(也就是栈底), 所以 ebp 的用途是在堆栈中寻址
esp 会随着数据的入栈和出栈而移动, 即 esp 始终指向栈顶
call _add做了什么(感觉不到)1
把`call _add`下一条指令的地址压栈
_add: push ebp做了什么(感觉不到)1
把`esp`指向`add`函数的`ebp`
ret做了什么(感觉不到)- 把 ebp 内的内容复制到 esp 寄存器中, 也就是 B 函数的栈基作为原有调用者A 函数的栈顶
- 弹出栈顶元素, 放到 ebp 寄存器中, 因为原有 A 函数的栈基指针压到了内存里, 所以弹出后, 放入 ebp, 这样原函数 A 的现场恢复完毕
pop ebp把返回地址和main的ebp都弹栈出去1
2mov esp,ebp
pop ebp
- 下面的
.dump文件中的e8代表call, 而ab ff ff ff是通过00401510减去401565所得
1 |
|
1 | .file "main.c" |
1 | #include <stdio.h> |
文件的操作
1 | struct _iobuf { |
- Windows 操作系统下的 FILE 结构体与 Linux 操作系统, Mac 操作系统下的 FILE 结构体中的成员变量名是不一致的, 但是其原理可以互相参考
C 文件概述
程序执行时就称为进程, 进程运行过程中的数据均在内存中
需要存储运算后的数据时, 就需要使用文件。这样程序下次启动后, 就可以直接从文件中读取数据
文件是指存储在外部介质(如磁盘、磁带)上的数据集合, 操作系统是以文件为单位对数据进行管理的
缓冲文件系统: 系统自动地在内存区为每个正在使用的文件开辟一个缓冲区。用缓冲文件系统进行的输入/输出称为高级磁盘输入/输出。非缓冲文件系统: 系统不自动开辟确定大小的缓冲区, 而由程序为每个文件设定缓冲区。用非缓冲文件系统进行的输入/输出称为低级输入/输出。
缓冲区其实就是一段内存空间, 分为读缓冲、写缓冲。C 语言缓冲的三种特性如下:全缓冲: 在这种情况下, 当填满标准 I/O 缓存后才进行实际 I/O 操作。全缓冲的典型代表是对磁盘文件的读写操作。行缓冲: 在这种情况下, 当在输入和输出中遇到换行符时, 将执行真正的 I/O 操作。这时, 我们输入的字符先存放到缓冲区中, 等按下回车键换行时才进行实际的 I/O 操作。典型代表是标准输入缓冲区(stdin)和标准输出缓冲区(stdout)。不带缓冲: 也就是不进行缓冲, 标准出错情况(stderr)是典型代表, 这使得出错信息可以直接尽快地显示出来
输出文件缓冲区和输入文件缓冲区是同一个缓冲区标准输入缓冲区(stdin)和标准输出缓冲区(stdout)不是
文件打开及关闭
fopen函数用于打开由 fname(文件名)指定的文件, 并返回一个关联该文件的流r打开一个用于读取的文本文件w创建一个用于写入的文本文件, 如果存在会清空文件a附加到一个文本文件,文件存在不会清空文件rb打开一个用于读取的二进制文件wb创建一个用于写入的二进制文件ab附加到一个二进制文件r+打开一个用于读/写的文本文件w+创建一个用于读/写的文本文件a+打开一个用于读/写的文本文件rb+打开一个用于读/写的二进制文件wb+创建一个用于读/写的二进制文件ab+打开一个用于读/写的二进制文件
fclose函数用于关闭给出的文件流, 并释放已关联到流的所有缓冲区fputc函数用于将字符 ch 的值输出到 fp 指向的文件中fgetc函数用于从指定的文件中读入一个字符, 该文件必须是以读或读写方式打开的- perror 函数是读取错误码来分析失败原因的
1 |
|
1 | ciallociallociallo |
文件读写
fread函数与fwrite函数- fread 函数的返回值是读取的内容数量
- fwrite 写成功后的返回值是已写对象的数量
1 | int fread(void *buffer, size_t size, size_t num, FILE *stream); |
fread 和 fwrite 函数既可以以文本方式对文件进行读写, 又可以以二进制方式对文件进行读写
- fgets 函数与 fputs 函数
- 函数 fgets 从给出的文件流中读取[num-1]个字符, 并且把它们转储到 str(字符串)中。
- fgets 在到达行末时停止, fgets 成功时返回 str(字符串), 失败时返回 NULL, 读到文件结尾时返回 NULL
- fputs 函数把 str(字符串)指向的字符写到给出的输出流。成功时返回非负值, 失败时返回 EOF
1 | char *fgets(char *str, int num, FILE *stream); |
- 使用 fgets 函数, 我们可以一次读取文件的一行, 这样就可以轻松地统计文件的行数
- 用于 fgets函数的 buf 不能过小(buf 大于最长行的长度), 否则可能无法读取”\n”, 导致行数统计出错
- fputs 函数向文件中写一个字符串, 不会额外写入一个”\n”
fgetc fputc fgets fputs 只能读取字符串
windows下(在 Mac 和 Linux 操作系统下并不存在这样的问题)以文本方式下写入”\n”后, 磁盘存储的是”\r\n”, 当然读取”\r\n”时底层接口会自动转换为”\n”。而以二进制方式写入”\n”后, 磁盘存储的是”\n”,二者在其他方面没有差异
写入整型数, 浮点数时, 一定要用二进制方式时, 需要以”rb+”方式打开文件
二进制方式下内存中存储的是什么, 写入文件的就是什么, 是一致的
如果是以文本方式写入的内容, 那么一定要以文本方式读取如果是以二进制方式写入的内容, 那么一定要以二进制方式读取, 不能混用!
1 |
|
1 | ciallo |
1 |
|
1 | i=0 |
1 |
|
1 | ciallo |
文件位置指针偏移
fseek 函数的功能是改变文件的位置指针
fseek(文件类型指针,位移量,起始点)- 位移量是指以起始点为基点, 向前移动的字节数。一般要求为 long 型
- fseek 函数调用成功时返回零, 调用失败时返回非零
起始点的说明如下:
- 文件开头
SEEK_SET0 - 文件当前位置
SEEK_CUR1 - 文件末尾
SEEK_END2
- 文件开头
1 | int fseek(FILE *stream, long offset, int origin); |
- ftell 函数返回 stream(流)当前的文件位置, 发生错误时返回-1
- 当我们想知道位置指针距离文件开头的位置时, 就需要用到 ftell 函数
1 | long ftell(FILE *stream); |
1 |
|
1 | now pos=8 |


